This page is adapted from my book, Enterprise Intelligence, Relational Models are Ontologies, page 111.
In the journey toward a truly intelligent enterprise—one with an Enterprise Knowledge Graph (EKG) that reasons over curated BI, domain expertise, and real-time data—the hardest part isn’t always building the graph from scratch. Often, the richest starting material already sits in your relational databases: schemas that quietly encode business reality through tables, keys, and relationships.
Consider Figure 1, a simple dimensional model for stock quotes (a classic Fact-Dimension setup):
- Foreign Key Relationship―The connection between FactQuotes and DimStocks
is labeled as a foreign key (FK) relationship. This indicates that StockID in
FactQuotes is a reference to StockID in DimStocks.- Semantic triple: Stocks have Quotes.
- Event Classification― FactQuotes is classified as an event, which is appropriate
since a quote is an occurrence at a point in time.- Semantic triple: Quotes have Timestamp
- Unit of Measurement―Unit associated with Quote, which implies that quotes
can have different units of measurement. This is a nuanced way of representing
the data and aligns with more detailed data models.- Semantic triple: Quote has property Unit
- Primary Key Identification―StockID and TraderID are identified as primary
keys for their respective tables, which is fundamental in database design.- Semantic triple: Stocks has ID, Traders has ID
- Taxonomy―The ParentTraderID in DimTraders suggests a hierarchical
relationship within traders, which is an example of taxonomy or inheritance.- Semantic triple: Traders childof Parent.
See RDF for Figure 1 for a more technical breakdown, an idea of what Figure 1 might look like in RDF.
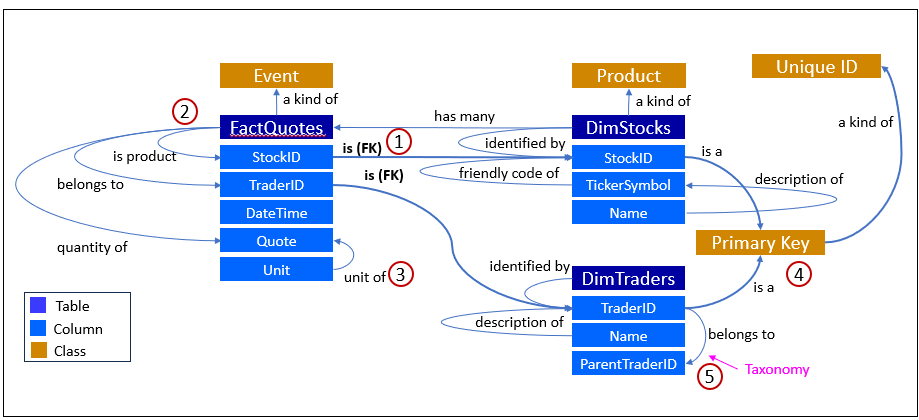
At first glance, this looks like “just” a database schema—optimized for queries, joins, and analytics. But it’s already an informal ontology, formed from the data modelers who created this schema. Tables act as classes (Event, Product/Stock, Trader); columns as properties (has Quote, identified by TickerSymbol); foreign keys as object properties (belongs to Trader, has many Quotes); and the ParentTraderID hints at inheritance or hierarchical classification.
Relational schemas could be thought of as “proto-ontologies”—they define entities, relationships, and constraints, just not in a machine-reasonable, semantic form. They’re “relational” in the loose sense (keys link tables), but lack the rich expressivity of OWL/RDF: no explicit “is-a-kind-of” for classification, no formal units/taxonomies, no inference rules.
RDF for Figure 1
This section provides a more technical explanation of Figure 1. The sample code is in the turtle format—a compact, human-readable syntax for writing RDF triples.
One important caveat: the IRIs used here for classes, properties, and individuals (ex. :Stock, stock_AAPL) are simplified placeholders based on table names and primary keys. In a production or truly semantic setting, good IRIs require more care—they need stable namespaces (often a base URI like http://myenterprise.com/ontology/), global uniqueness, and often resolution to authoritative external identifiers (ex. Wikidata QIDs for common concepts). Handling ambiguity in labels, disambiguating contextually, querying multiple sources in parallel, caching results, and incorporating governance for trust turn IRI assignment into a substantial topic of its own. We’ll explore that dynamic process in more detail in a future post on the Explorer Subgraph and relation space navigation. We’ll talk about this more in the International Resource Identifier topic.
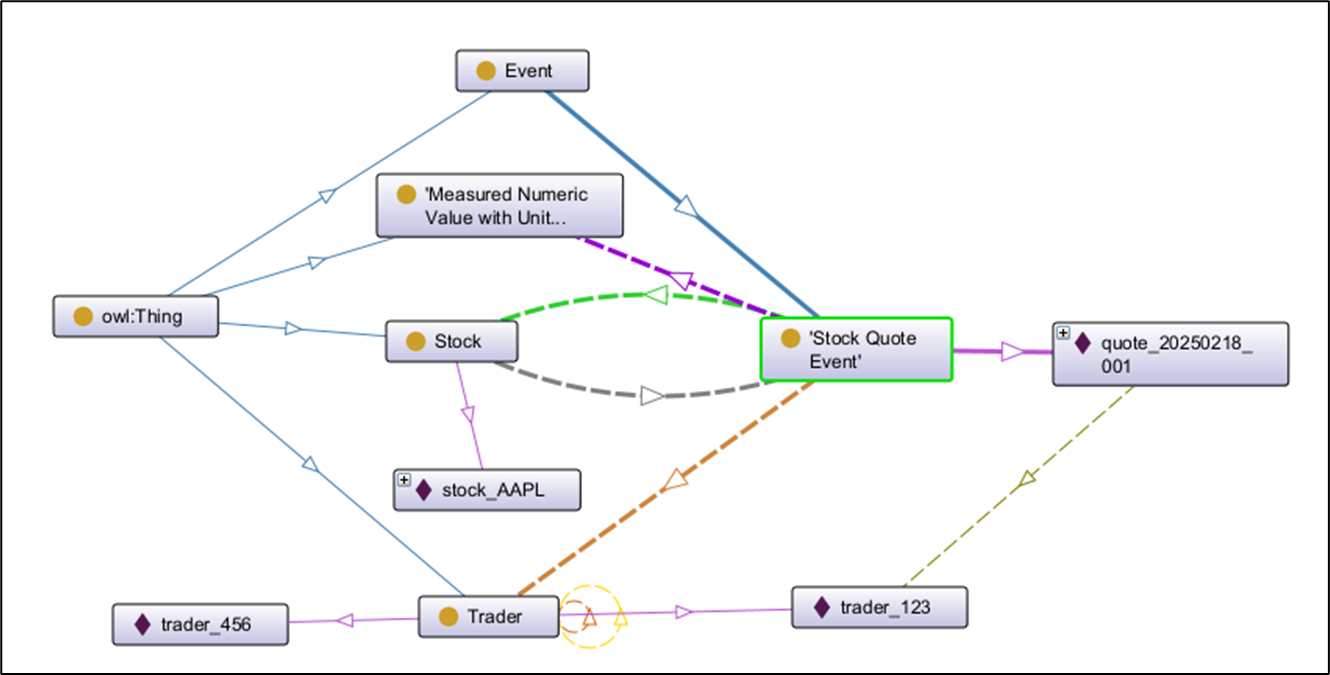
Figure 2 illustrates what the RDF will look like at the end of this topic as viewed through Stanford Protege.
1. Foreign Key Relationship – Stocks have Quotes
This represents the FK from FactQuotes to DimStocks (ex. via StockID). In Semantic Web terms, this is an object property linking classes. Suggested triples/axioms:
:Stock rdf:type owl:Class . # DimStocks table as a class:Quote rdf:type owl:Class . # FactQuotes table as a class (events):hasQuote rdf:type owl:ObjectProperty ; # Inverse of the FK direction rdfs:domain :Stock ; rdfs:range :Quote .:Quote owl:inverseOf :belongsToStock . # Optional: bidirectional for queryingUse owl:ObjectProperty for entity-to-entity links. This allows inferences like “a stock has multiple quotes”. Add cardinality if needed (ex. owl:cardinality for 1:N relationships).
2. Event Classification – Quotes have Timestamp
This classifies FactQuotes as an event with a timestamp property. Suggested triples/axioms:
:Quote rdf:type owl:Class ; rdfs:subClassOf :Event . # Classify as event:hasTimestamp rdf:type owl:DatatypeProperty ; rdfs:domain :Quote ; rdfs:range xsd:dateTime .:Quote owl:hasKey ( :hasTimestamp ) . # If timestamp uniquely identifies quotes (composite with others?)Subclass :Quote under an :Event class for classification. Use xsd:dateTime for the timestamp to enable temporal queries. If it’s part of a key, add owl:hasKey.
3. Unit of Measurement – Quote has property Unit
This associates a unit (ex. currency) with the quote value. Suggested triples/axioms:
:Quote rdf:type owl:Class .:hasValue rdf:type owl:ObjectProperty ; # Structured value for amount + unit rdfs:domain :Quote ; rdfs:range :MeasuredValue .:MeasuredValue rdf:type owl:Class . # Reified node for value:amount rdf:type owl:DatatypeProperty ; rdfs:domain :MeasuredValue ; rdfs:range xsd:decimal .:unit rdf:type owl:DatatypeProperty ; # Or object property to a unit class rdfs:domain :MeasuredValue ; rdfs:range xsd:string . # E.g., "USD"; use QUDT for more precisionExample instance:
:quote1 :hasValue _:val1 ._:val1 :amount "428.50"^^xsd:decimal ; :unit "USD" .Explanation: Avoid embedding units in strings; use a reified :MeasuredValue class (blank node pattern) for queryability. For standards compliance, link :unit to QUDT (ex. <http://qudt.org/vocab/unit/USD>).
4. Primary Key Identification – Stocks has ID, Traders has ID
This identifies primary keys like StockID and TraderID. Suggested triples/axioms:
:Stock rdf:type owl:Class .:hasID rdf:type owl:DatatypeProperty, owl:InverseFunctionalProperty ; # Globally unique rdfs:domain :Stock ; rdfs:range xsd:string . # Or xsd:integer if numeric:Stock owl:hasKey ( :hasID ) . # OWL 2 key axiom:Trader rdf:type owl:Class .:hasID rdf:type owl:DatatypeProperty, # Reuse property if generic owl:InverseFunctionalProperty ; rdfs:domain :Trader ; rdfs:range xsd:string .:Trader owl:hasKey ( :hasID ) .Use owl:hasKey for class-specific keys (best for RDB mapping). Add owl:InverseFunctionalProperty for global uniqueness, triggering owl:sameAs inferences if IDs match.
5. Taxonomy – Traders childof Parent
This represents the hierarchical ParentTraderID in DimTraders (self-referential FK for hierarchy). Suggested triples/axioms:
:Trader rdf:type owl:Class .:hasParent rdf:type owl:ObjectProperty ; # Self-referential rdfs:domain :Trader ; rdfs:range :Trader .:hasChild owl:inverseOf :hasParent . # For bidirectional traversal:TraderHierarchy rdf:type owl:Class ; # Optional: reify hierarchy rdfs:subClassOf skos:ConceptScheme . # Use SKOS for taxonomiesExample instance (tree structure):
:trader1 :hasParent :parentTrader .:trader2 :hasParent :trader1 . # Builds hierarchyModel as a transitive object property if needed (add owl:TransitiveProperty for ancestor inference). For pure taxonomies, integrate SKOS (skos:broader/skos:narrower) for broader/narrower relationships.
Populating Individuals from Table Data
While the schema defines the structure—classes from tables, properties from columns, relationships from foreign keys—the actual individuals (instances) in the resulting ontology come from the rows in those tables.
In RDF terms:
- Each row in a table (or the result of a SQL query/view that represents a meaningful entity) becomes an individual (named resource) belonging to the corresponding class.
- The primary key value(s) typically serve as the basis for generating a unique IRI for that individual.
- Column values become property assertions (data properties for literals, object properties for foreign-key-linked entities).
Examples in RDF/Turtle syntax:
# From DimStocks table → :Stock class:stock_AAPL rdf:type :Stock ; :hasTickerSymbol "AAPL"^^xsd:string ; :hasCompanyName "Apple Inc."^^xsd:string .# From FactQuotes table (or a view joining quotes + stock + trader):quote_20250218_001 rdf:type :Quote ; :ofStock :stock_AAPL ; :tradedBy :trader_123 ; :hasTimestamp "2025-02-18T14:30:00Z"^^xsd:dateTime ; :hasCloseValue [ :amount "428.50"^^xsd:decimal ; :unit "USD" ] .# From DimTraders table (hierarchical):trader_456 rdf:type :Trader ; :hasName "Jane Doe"^^xsd:string ; :hasParent :trader_123 . # builds the taxonomyTo generate these triples automatically:
- Execute a SELECT * FROM table_name (or a denormalized view/query that joins related dimensions) for each relevant table.
- For each row, construct an IRI (e.g., using a base URI + table name + primary key value: ex:stock_{StockID}).
- Map each non-key column to a property assertion.
- Handle foreign keys by linking to the IRI of the referenced individual.
This step turns the static schema (TBox: classes, properties, axioms) into a populated knowledge graph (ABox: individuals + facts), enabling real semantic querying, inference, and LLM grounding over your actual business data.
Automation
Automating this doesn’t require fantastically complicated code. With data model views (DMV), LLMs as semantic translators and Python magic (this is probably simple enough for an LLM to generate the code)—we can start lifting these schemas into proper ontologies and taxonomies.
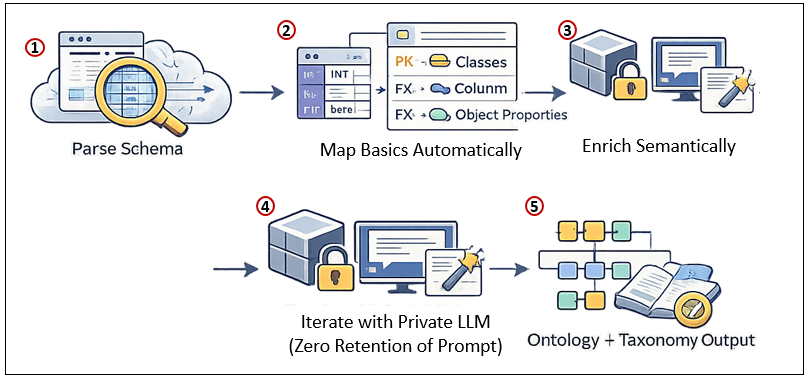
- Parse the schema (tables, columns, PK/FK constraints, data types).
- Map basics automatically: Tables → Classes, Columns → Data Properties, FKs → Object Properties.
- Enrich semantically: Infer “is-a-kind-of” from naming patterns or metadata (ex. FactQuotes as subclass of Event); detect hierarchies (ParentTraderID → taxonomic parent-child); add units/domains from column metadata or documentation.
- Iterate with LLM assistance (private endpoint, zero-retention): Prompt for refinements like “Given this FK chain and column names, suggest OWL axioms for classification and measurement units.”
- Output a seed ontology (OWL/TTL) + taxonomy (hierarchical classes) that feeds your EKG—grounded in real enterprise data, not abstract theory.
The result probably will not be perfect (schemas often hide nuances), but it’s a massive accelerator to bootstrap your EKG from what you already have, then refine with SME input, BI insights, and story-like narratives (as we’ve discussed). No more starting from blank pages—your databases become the living seed for symbolic reasoning.
This bridges the old world (efficient relational ops) and the new (semantic inference, LLM orchestration). It’s a pragmatic step toward enterprises where knowledge isn’t siloed in tables or prompts—it’s explicitly modeled, evolvable, and sovereign.
International Resource Identifier
In these examples, we’ve used simple, locally generated IRIs (ex. :stock_AAPL) derived directly from table names and primary keys for clarity and ease of generation. In a more robust, production-ready semantic setup, we want to resolve these to stable, globally unique IRIs—ideally linking to authoritative sources like Wikidata QIDs (as shown in the table above) for common concepts, or to enterprise-specific namespaces when no public match exists.
This helps with interoperability, disambiguation, and reuse across systems—which is the entire idea behind the Semantic Web. However, reliably finding the “right” external IRI isn’t always straightforward: labels can be ambiguous, context matters, multiple candidates may exist, and lighter-weight LLM deployments (without full context windows or advanced tooling) often struggle with precise matching. For that reason, production IRI resolution—querying Wikidata/DBpedia in parallel, scoring confidence, caching results, handling provisional terms, and applying governance—is a significant topic in its own right.
Here’s a tight summary of the few most important reasons why getting/assigning the right IRI is a whole separate, advanced topic (not something to squeeze into the basic auto-generated ontologies post):
- High ambiguity in real-world labels Common words (e.g., “corn”, “apple”, “bank”) map to many completely different entities. Resolving which one is meant requires semantic interpretation of context, not just string matching—often needing an LLM to disambiguate intent before any lookup.
- Multi-source, parallel querying is required for reliability No single source (Wikidata, DBpedia, schema.org, etc.) has every answer. The system must query several in parallel, collect candidates, compare them (via embeddings, confidence scores, or LLM judgment), and merge or select—far more than a simple namespace prefix + PK concatenation.
- Probabilistic & non-deterministic elements dominate LLMs introduce variability (different outputs on the same input, hallucinations, latency, cost), so resolution relies on similarity scoring, confidence thresholds, caching, and fallback strategies. Pure deterministic rules break easily; the process is inherently probabilistic.
- Production constraints force trade-offs Enterprise deployments use lighter API-based LLMs (smaller context, no orchestration/tools) that perform worse than chat versions. This makes robust disambiguation harder and pushes reliance on structured pipelines, vector caches, and governance rather than “just ask the LLM.”
- Novel/enterprise-specific concepts have no public match Internal codes, new products, proprietary terms, or post-training knowledge gaps mean no Wikidata QID exists. The system must handle “unknowns” gracefully: provisional IRIs, rich descriptions, logging for review, human escalation, and ongoing governance—turning IRI assignment into a living, governed process.
In essence, basic local IRIs (like :stock_AAPL) are fine for demos and bootstrapping, but real semantic interoperability demands a full dynamic resolution engine—parallel, probabilistic, governed, and integrated with the Explorer Subgraph. That’s why it’s deliberately treated as its own subject.
My blog, Explorer Subgraphs, explains much of this since I had to deal with this problem there. Specifically, the topic, Seeding the Explorer Subgraph with Database Tables, discusses the general idea.
Table 1 shows the object we’ve looked at and their corresponding IRI (a Wikidata QID).
| Local Class/Property/Individual Type | Example Local IRI | Corresponding Wikidata Concept | Wikidata QID | Notes |
|---|---|---|---|---|
| Stock (class) | :Stock | Financial security / stock | Q1196314 | Broad class for shares/securities; specific stocks (e.g., Apple) would link via ticker or company. |
| Quote / Trade Event (class) | :Quote | Financial transaction / stock quote | Fits time-stamped quote or trade event; subclass of :Event. | |
| Ticker Symbol (property value) | “AAPL” (via :hasTickerSymbol) | Stock ticker symbol | Q1548784 | The concept of a ticker symbol itself; individual symbols often link to company QIDs. |
| Company (via property) | “Apple Inc.” (via :hasCompanyName) | Public company / corporation | Q783794 | Use company-specific QID when available; fallback to general “corporation”. |
| Trader (class) | :Trader | Trader / investor (financial) | Entity engaging in trades; often a person or institution. | |
| Measured Value / Price (reified) | :MeasuredValue with :amount & :unit | Monetary value / price | For the reified value with unit (e.g., USD → Q4916 for United States dollar). |
