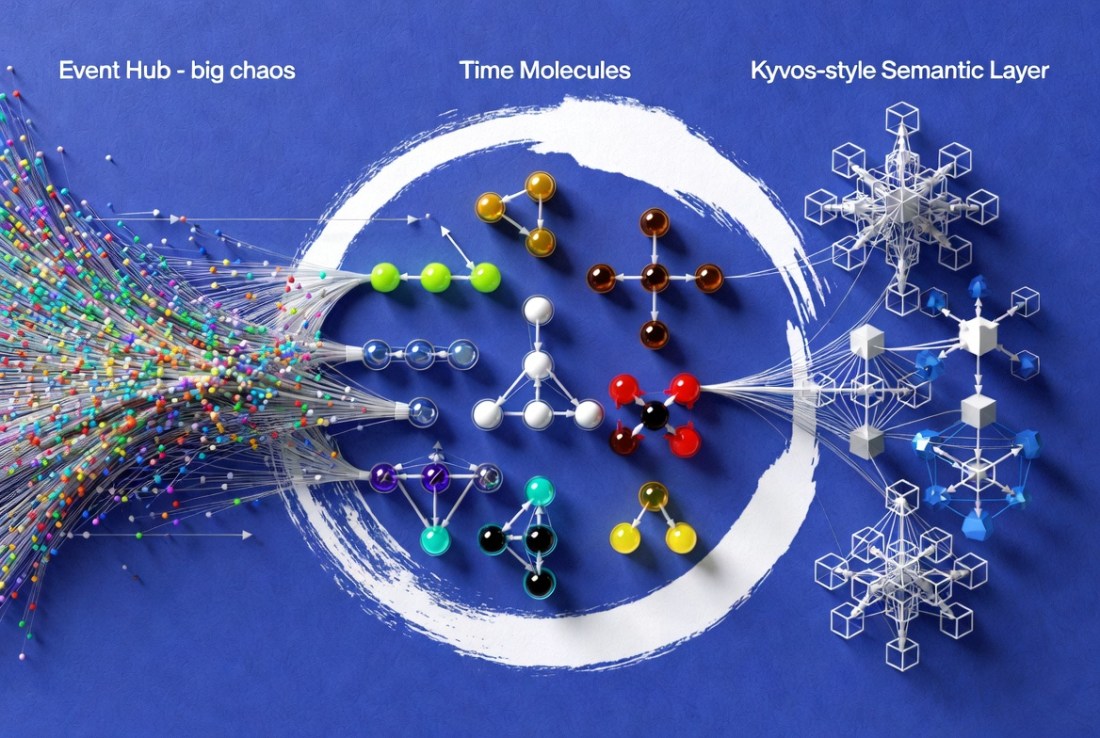
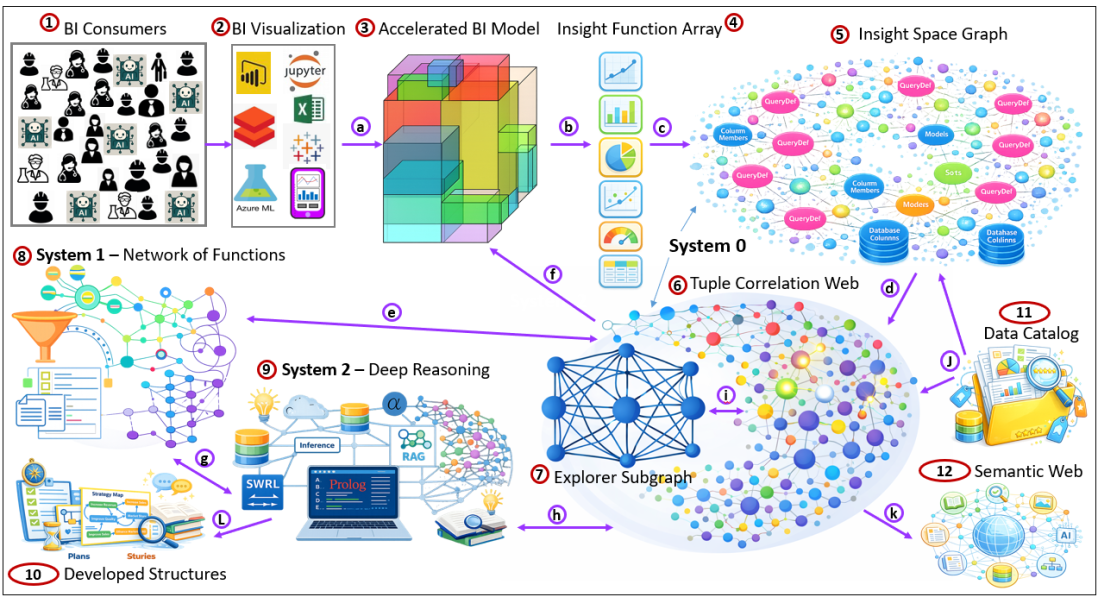
This blog describes the Time Molecules process for the analysis of adversarial situations. That includes frauds, competitive games such as Texas Hold'em Poker, and any other situation where imperfect information is the key asset. Beyond sheer skill, good adversaries rely on stealth, sleight-of-hand, misinformation/disinformation, information overload, mimicry (impersonation), etc. Adversaries paint a false picture for … Continue reading Seeing the Hook through the Uncanny Valleys Encountered by an Enterprise
Seeing the Hook through the Uncanny Valleys Encountered by an Enterprise