TL;DR
For enterprises pursuing Enterprise Intelligence—a cohesive framework that integrates Business Intelligence (BI) as the foundational spearhead, data mesh for decentralized governance and scalability, knowledge graphs (especially the central Enterprise Knowledge Graph or EKG) for structured, hallucination-resistant reasoning, and LLMs as connective “mortar” to interpret, augment, and query across these layers—the best practical path forward in 2026 is to prioritize owning and controlling your Retrieval-Augmented Generation (RAG) layer while adopting a hybrid LLM deployment strategy.
Build your private, sovereign RAG infrastructure (using vector databases, semantic search, access controls, prompt redaction, and revocable knowledge sources like documents, BI insights, ontologies, and SME-authored content) to ensure proprietary enterprise knowledge—strategies, policies, plans, regulated data, and domain-specific context—never leaves your governed boundary. This aligns directly with the Enterprise Intelligence vision of grounding AI in curated, trustworthy sources via the EKG and data mesh principles, minimizing risks like hallucinations, data leakage, or over-reliance on ungrounded models.
For the LLM inference itself, default to high-capability external models (ex. via secured APIs from OpenAI Enterprise, Anthropic, or hyperscaler-managed services like Azure OpenAI, Amazon Bedrock, or Google Vertex AI) for most tasks involving public knowledge, general reasoning, code generation, or creative synthesis—these offer the strongest performance at lower cost and ops burden, with strong default privacy protections (no training on your data, transient processing). Reserve fully private LLM deployments (self-hosted open-weights models on your cloud tenant’s GPU instances or on-prem hardware) for ultra-sensitive domains where even API-level exposure is unacceptable, such as classified strategies or high-compliance workloads.
This hybrid posture—sovereign RAG + hybrid LLM access—delivers the optimal balance: maximum control over your business’s proprietary intelligence, robust governance and auditability, reduced infrastructure headaches, and access to frontier-level reasoning without unnecessary expense or complexity. It positions LLMs as true assistants within my intelligence of a business framework, augmenting human knowledge workers and BI rather than replacing them, while future-proofing your architecture for evolving models and regulations. Start here, audit prompt flows rigorously, and plan for easy swapping of LLM providers to maintain portability.
Do we (the enterprise) need to own the Retrieval Augmented Generation (RAG)?
Yes: In most serious enterprise architectures.
RAG is where your proprietary knowledge lives:
- Strategies
- Plans
- Operating procedures
- Policies
- Product roadmaps
- Internal data
Even when using an external LLM via API, best practice is:
The enterprise owns the retrieval layer, while the LLM provides reasoning and translation.
This ensures:
- Access control by role
- Auditability
- Revocation of knowledge
- Update without retraining models
What is RAG (Retrieval-Augmented Generation) in Simple Terms?
RAG is the most common way enterprises safely use LLMs with private knowledge.
In simple terms:
RAG means the enterprise keeps its knowledge in its own systems, retrieves only what is needed for a question, and gives that excerpt to the LLM to reason over.
The LLM does not “know” your strategies, plans, or documents ahead of time. It only sees the specific content retrieved for that request.
Think of it like this:
- Your enterprise knowledge is a secure library.
- RAG is the librarian who fetches relevant pages.
- The LLM reads those pages and answers the question.
- The pages go back on the shelf afterward.
The LLM never owns the library.
Why Enterprises Use RAG
RAG allows organizations to:
- Keep proprietary knowledge private
- Control who can retrieve what
- Update knowledge instantly
- Avoid retraining models
- Audit what content was used in answers
This makes it the safest and most governable way to apply LLM reasoning to enterprise knowledge.
Common Enterprise RAG Components (High Level)
You do not need to understand the technical internals, but most RAG systems include:
- Knowledge sources
- Documents, databases, knowledge graphs, policies
- Search/retrieval layer
- Finds relevant content for a query
- LLM reasoning layer
- Interprets and synthesizes the retrieved content
Vendor Examples — RAG Tooling
Enterprises can build RAG using many platforms. Examples include:
Cloud platform RAG ecosystems
- Microsoft Azure — Azure AI Search + Azure OpenAI
- Amazon Web Services — Bedrock + Knowledge Bases
- Google Cloud — Vertex AI Search + Generative AI
These platforms provide end-to-end RAG building blocks.
Vector database / retrieval vendors
These specialize in storing and retrieving knowledge embeddings:
- Pinecone
- Weaviate
- Chroma
- Elastic (vector search in Elasticsearch)
Enterprise AI orchestration frameworks
These help wire retrieval + prompting + LLM calls:
- LangChain
- LlamaIndex
- Haystack
Key Principle
Enterprises do not put their knowledge inside LLMs.
They retrieve knowledge when needed and let the LLM reason over it.
This preserves:
- Privacy
- Governance
- Vendor portability
- Strategic control
Recommended RAG Architecture (2026 Best Practice)
1. Source layer
- Document stores
- Knowledge graphs
- Rule systems (e.g., Prolog)
- Databases / BI systems
2. Ingestion + chunking
- Semantic chunking (not fixed tokens)
- Metadata tagging
- Sensitivity classification
3. Embeddings
- Private embedding model
- Versioned vectorization
4. Vector store
- Access-controlled
- Tenant-isolated
- Audited queries
5. Retrieval orchestration
- Query rewriting
- Hybrid search (semantic + keyword)
- Re-ranking
6. Prompt assembly
- Minimal excerpt inclusion
- Policy filtering
- Redaction if needed
7. LLM inference
- External or private model
Key principle:
Plans and strategies live in RAG sources (ex. internal documents, databases, knowledge graphs)—not in model weights.
If we use an external LLM API, is our data used for training or otherwise exposed (even if cleansed)?
Major enterprise AI vendors now publish clear policies. Below, I list the policies of major AI vendors as of February 18, 2026. But please be sure to check this for yourself.
OpenAI (API & Enterprise)
- Business/API data is not used for training by default.
- Abuse monitoring logs may be retained (typically up to 30 days).
- “Zero Data Retention” may be available for qualifying use cases.
Anthropic (Claude commercial products)
- Commercial/API data is not used for training by default.
Cloud wrapper services (e.g., AWS Bedrock)
- Prompts/responses are not used to train underlying models.
- Providers state they do not distribute that data to third parties.
Important nuance
Even with strong privacy terms:
- Vendors may retain limited logs for abuse monitoring.
- Legal orders can compel retention or disclosure.
- Policies can evolve over time.
So architectural risk mitigation still matters. In other words, they AI vendor could just change their mind some time down the road.
Is using an external LLM private to the customer? Like it would be for email or other cloud service.
Conceptually similar, but with caveats.
Email systems:
- Store your content.
- You control tenancy.
- Providers act as custodians.
External LLM APIs:
- Process your content transiently.
- May retain short-term logs.
- Provide contractual privacy assurances.
So they are operationally private, but not sovereign in the same way as on-prem systems.
Do we (an enterprise) need a fully private (on-prem) LLM?
It depends on what you send to the model. However, for the intelligence of a business framework, it should be private.
You likely need private deployment if prompts contain:
- Strategy or competitive plans
- Security posture
- Initiatives such as M&A activity
- Military, healthcare, or regulated data
- Proprietary manufacturing logic
You may not need it if prompts contain only:
- Public knowledge reasoning
- Code generation
- Generic drafting
- Sanitized summaries
Many enterprises adopt a hybrid posture:
External LLM for “public cognition”
Private systems for “strategic cognition”
Regarding private LLMs, what is an “open-weight” model?
An open-weight model means:
- The trained parameters (weights) are downloadable.
- You can run the model yourself.
- You can fine-tune privately (license permitting).
This is different from fully open-source:
- Training data is usually not provided.
- Full reproducibility is rare.
Examples include families like Llama, Mistral, etc.
6) Does a private LLM deployment require buying .
Do we need our own GPUs and to install them ourselves like in the pre-cloud days?
Not necessarily. If you want “private LLM” behavior (ex. prompts and retrieved enterprise knowledge don’t spill into uncontrolled environments), there are three common deployment patterns:
A) On-prem hardware (you own the GPUs)
- What it is: You buy and run GPU servers in your own data center.
- Privacy posture: Maximum sovereignty. Data stays on your network.
- Tradeoffs: Highest upfront cost, hardest ops (drivers, CUDA stack, patching, monitoring, capacity planning).
Typical fit: air-gapped / classified / “we must control everything” environments.
B) Private cloud deployment (you rent GPUs, but keep a private boundary)
- What it is: You deploy the model (or an open-weights model server) inside your own cloud tenant (your VPC/VNet).
You don’t own GPUs; you use cloud GPU instances. - Privacy posture: Strong isolation within your tenant. You control networking, IAM, and data stores. With proper setup, prompts and RAG content never leave your cloud boundary.
- Tradeoffs: Still your ops responsibility (deployment, scaling, patching), but no physical hardware procurement.
Vendor examples (Pattern B):
- AWS: EC2 GPU instances + your own model serving (vLLM/TGI/etc.), or Amazon Bedrock in your AWS account boundary.
- Azure: Azure GPU VMs + your serving stack, or Azure OpenAI Service within Azure tenant controls.
- Google Cloud: GCE GPU instances + your serving stack, or Vertex AI within GCP controls.
Typical fit: most enterprises that want strong privacy without owning hardware.
C) Managed private model hosting (dedicated instance, vendor runs it)
- What it is: A provider hosts a dedicated/private model environment for you (often single-tenant or capacity-reserved). You get strong contractual controls; they run the infra.
- Privacy posture: You get contractual + technical guarantees (retention controls, no training by default, audit terms), and the vendor operates the stack.
- Tradeoffs: Less flexibility than running it yourself; you rely on the provider’s controls and contracts.
Vendor examples (Pattern C):
- OpenAI: enterprise offerings that support stronger data controls (and, for some customers/use cases, special retention arrangements).
- Anthropic: enterprise offerings with business-data protections and options aimed at regulated customers.
- Hyperscalers also offer managed variants (depending on service): “managed endpoint” style deployments where you don’t operate the serving layer day-to-day.
Typical fit: “we need strong privacy guarantees and minimal ops burden.”
Which is most common?
Pattern B (private cloud deployment) is the most common compromise today because it avoids GPU procurement and still lets you keep the model + RAG inside a controllable enterprise boundary.
What does a private LLM deployment stack look like?
Typical architecture:
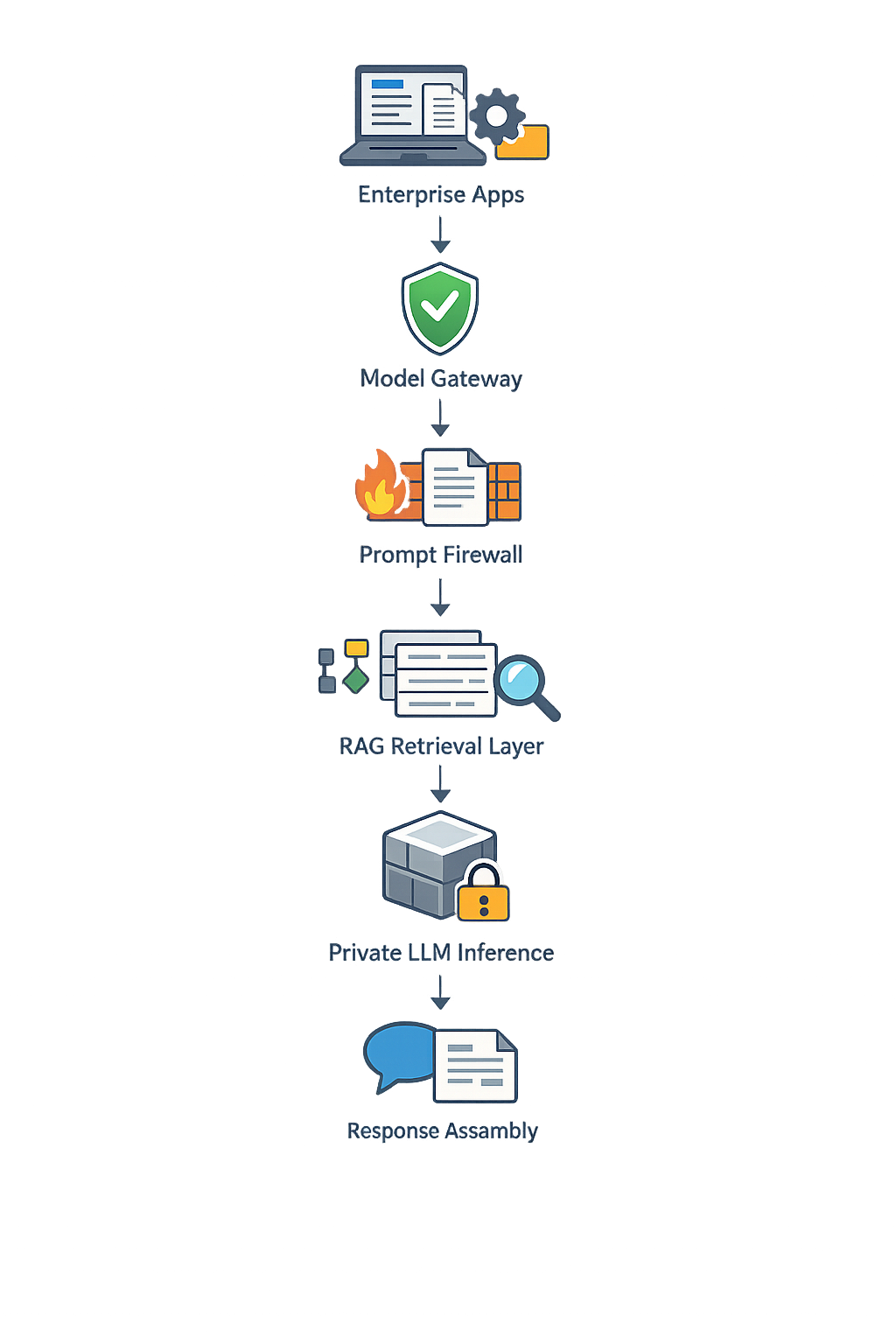
Key controls:
- Identity & access management
- Network isolation
- Audit logging
- Data retention policies
- Model version governance
Should sensitive knowledge be fine-tuned into the model, even if we’re using a private LLM?
Usually no.
Better pattern:
| Knowledge type | Storage location |
|---|---|
| Plans / strategy | RAG / Prolog / KG |
| Policies | Rule systems |
| Procedures | Docs / graphs |
| Translation behavior | Fine-tuning |
Reason:
- RAG knowledge is revocable.
- Model weights are not easily “unlearned.”
What is the most balanced enterprise approach today?
A widely adopted pattern:
- Enterprise-owned RAG
- Enterprise rule/graph systems
- External LLM via secured API
- Prompt redaction + policy gateway
- Optional private LLM for sensitive domains
This balances:
- Cost
- Capability
- Governance
- Infrastructure feasibility
If infrastructure shortages make private LLM difficult, what should we do?
Interim best practice:
- Own the RAG layer.
- Minimize prompt sensitivity.
- Use enterprise privacy APIs.
- Abstract strategies into IDs/tokens.
- Log and audit all LLM usage.
- Maintain portability to swap models later.
This keeps your architecture stable while infrastructure markets mature.
Authoring Sensitive Logic such as Prolog, Knowledge Graphs, and Strategy Maps with LLM Assistance
Since a primary theme of this post is that we can use LLMs to high-information artifacts such as Prolog, knowledge graphs, strategy maps, plans, the configuration trade-off graph, etc., we need to address sending prompts describing that sensitive information.
One practical way to mitigate this exposure while still leveraging LLMs for Prolog generation is to deploy them via a private endpoint in a controlled cloud environment, such as Azure OpenAI Service within your own Azure tenant (or equivalent offerings like Amazon Bedrock custom endpoints or Google Vertex AI private instances). In this setup, you use private networking (e.g., Azure Private Link or VNet integration) to ensure all traffic stays isolated within your enterprise boundary—no public internet routing, full data residency control, and enforcement of your IAM policies.
Critically, for sensitive rule-generation prompts containing strategic logic, business assumptions, or proprietary decision frameworks, opt for configurations that enable zero data retention (ZDR) or modified abuse monitoring—available to eligible enterprise customers (typically via Enterprise Agreement or Limited Access approval). Under these controls, prompts and completions are processed transiently in memory for inference only, with no persistent logging, storage beyond immediate abuse detection needs, or use for model training/improvement. This means the sensitive information in your prompt (e.g., internal policies or rule intent) is never retained in the LLM provider’s environment long-term.
Once generated, the Prolog code becomes a standalone, editable artifact under your full control—committed to your versioned knowledge base, audited, and executed deterministically—removing it from the fuzzy, non-deterministic world of LLM embeddings or weights. This hybrid yields strong security (isolation + encryption), sovereignty (you govern the boundary and can revoke/swap providers), and placement of strategic knowledge squarely in symbolic systems like Prolog, where it belongs.
