
The Two Sides of Embracing Enterprise Complexity
The Data Vault Methodology is a natural analytics counterpart to Domain Driven Design. They are two sides of the same coin. Both are about discovering and fully reflecting ever-changing enterprise processes. Both recognize that the ability to readily adapt and/or evolve systems to reflect change is key to continued success.
This blog is about about how these two highly sophisticated methodologies link. This is much like how Domain-Driven Design is already linked to other methodologies such as Functional Programming and Event Storming. In fact, both of those also play key roles in this blog, along with many other relatively recent buzzwords such as DevOps and ELT.
What’s unfortunate and surprising is that as of the date of this writing (December 2020), many of my BI colleagues have barely heard of Domain Driven Design (DDD), Data Vault Methodology (DVM), or both. In the context of my BI background, it’s not really too surprising since DDD is generally on the transactional (OLTP) side and the analytics (OLAP) side is still dominated by traditional star/snowflake data warehouses and more recent data lakes.
Both DDD and DVM are big subjects and there are very many excellent sources for either. But as far as I can tell, there is very little about DVM as a counterpart to DDD. I rarely hear DDD folks talking about the OLAP side – aside from Event Sourcing, which is another great story for another time. Nor do I hear analytics folks talk about the OLTP side, beyond a box on a PowerPoint slide labelled “Data Sources”.
So I need to provide background on a few substantial subjects – in fewer words than it would take to fill half a dozen books. Following are two illustrations that get to the punch line. Maybe that’s the TL;DR and it’s all you need to see.
Figure 1 is a map of how these weighty pieces relate. Notice Domain Model in the center. Although Domain Models are a product of DDD, it can play a key role in developing and maintaining a maximally valuable Data Vault.

Figure 2 illustrates the overall architecture of an OLTP and OLAP implementation tied together via the Domain Model. As with Figure 1, Domain Model is highlighted.

Agenda
The TL;DR for those who are DDD and DVM experts, I could have simply Tweeted the first sentence of this blog and be done. For those who are continuing, in this blog, I’ll provide:
- Minimal background on DDD and DVM.
- Address why DVM is a better choice for DDD than a traditional star/snowflake DW or simply dumping into a data lake.
- Describe the Domain Model of DDD and the Event Storming methodology used to create it.
- Describe how the marriage of DDD with functional programming (FP) smooths out the maintenance of the Domain Model.
- Explain how the Domain Model serves as a living blueprint for both DDD and DVM.
I’ll also include a number of links within most sections to what I think are the best videos on the subjects I cover. Additionally, there is a glossary at the end, due to the many acronyms.
Target Audience
I am a Business Intelligence (BI) Architect, so this blog skews towards a view through the analytics lens. My initial motivation for adopting the DVM was to help a customer find a way to provide analysts with immediate access to new data sources, albeit raw and dirty. That is, as opposed to waiting another few years for everyone to hammer out the complex web of competing goals. With relief to the analysts, which is much better than nothing, the rough edges could be smoothed out in a well-planned and iterative fashion.
This post is targeted towards:
- BI Architects of traditional star/snowflake schema data warehouses who are looking for a more versatile, adaptable, and scalable solution.
- Enterprise Architects unable to deliver changes to operational systems for various reasons, but must still provide immediate relief to analysts.
- For other IT folks in an IT department beginning to emerge from the 2000’s, this post could serve as a partial introduction into this strange IT world of the 2020’s.
The TL;DR for BI Architects simply seeking something more versatile than traditional star/snowflake data warehouses and want nothing to do with the OLTP side: Just read the two topics, Data Vault Methodology and Data Vault Implementation Issues.
Key Takeaways
These key takeaways make sense in the context of the first two items of the target audience.
- Be serious about “IT as a Strategic Asset”. IT (Information Technology) is not just plumbing. It can be the “ultimate employee”: tireless, ubiquitous, flawless memory, and malleable. But it requires the investment due a strategic asset. Instead, it’s looked upon as a cost center that should be minimized. The DDD and the DVM takes IT a long way from cost center to strategic asset.
- Take the time and expense needed to build solid, versatile platforms and systems. Integration of systems can be iterative if we ease up on waiting for perfection that may never and sometimes does not need to come along. A minimally OK answer is better than no answer, as long as there is a process to iteratively improve on it.
- IT systems need to be metadata-driven. DevOps should be about more than just pushing out software releases faster. At least to me, the true spirit of DevOps is: Instead of writing a program, write (or buy) a metadata-driven program to write the program.
Metadata-Driven and Metadata Management
I need to elaborate upon the 3rd Key Takeaway here. Towards the goal of embracing complexity, the concept of implementing the ideas in this blog in a metadata-driven manner is critical.
The Domain Model and the Data Vault configuration represent types of metadata-driven concepts. For example, from data vault metadata, Metadata-driven applications generate database schemas, ETL/ETL objects, deployment scripts, etc. Changes to the system are automatically propagated downstream and human errors are minimized.
Metadata Management is a map of everything – where the data is at, what it’s made of, who owns it, how it relates to other things. Tools such as Azure Purview (formerly Azure Data Catalog), collect metadata by interrogating databases, file systems, Web pages, etc., into a centralized and searchable place.
Metadata isn’t just about a catalog of things, such as column and table names, column types, and creation dates. Metadata should also include business rules, such as those for security and privacy, calculations, and event triggers. All of those rules will be centrally controlled mitigating the probability for missing something.
However, the boundaries between the two are blurred. For example, a Data Vault configuration tool, from which metadata-driven objects are generated, needs to have the ability to extract database metadata from data sources. Both are key towards the goal of automating IT. Metadata Management detects changes in data sources, which drives the Metadata-driven applications to regenerate code.
Cultural Shift is the Toughest Part
Before diving in, a word of warning you should keep in mind. The notion of developing and maintaining a Domain Model as a fully reflective map of the enterprise requires a cultural fit. It could be that a massive cultural shift is required, not just for IT and/or the “Office of Data Governance”. It includes everyone who requires information to do their job and generates information doing their job. It could be the toughest nut to crack.
A large part of that cultural shift centers around allowing for enough time to lay proper foundations (the 2nd key takeaway) and obsessively clean up as we go along. Just like we do to keep a tidy home.
Sometimes, it’s not practical to take the time to do things the “right” way, at least for the time being. Many IT shops have a backlog of hundreds of items due yesterday. Most of those hundreds of items will end up being yet another patch adding even more to the complexity. And there’s a good chance that tribal knowledge of those patches exists only in the head of a developer who will leave well before their 30th Anniversary lunch.
Keeping Up with Evolving Ecosystems – The Cause of the Pain
Hardly any of the point of this blog matters if everything changed very slowly. We could set up our systems once and manage to keep up with the pace of change. It will then be like plumbing. It takes a lot of skill to maintain plumbing, but it pretty much stays the same. But competition at many levels drives constant and considerable change across a wide enterprise landscape. We can resist it with patches until it explodes. Instead, we need to adopt processes built to embrace change.
Enterprises are complex systems. They are made up of departments, teams, professional “cultures” with their own jargon and customs, and employees all with minds of their own. All of these moving parts interact in a web of rules that are sometimes ambiguous, sometimes questionable, sometimes forgotten, sometimes misunderstood by others, often contradicting other rules, and most importantly, always changing.
The complexity of our enterprises contrasted with mechanical but very complicated software solutions represents quite a paradox. We attempt to tame a complex problem with solutions for complicated problems. As the ecosystem in which our enterprises operate relentlessly evolves, we herd it back into the conformity of our change-resistant software. Instead, how can we make our software more amenable to change?
This was recognized and addressed about a couple decades ago by Eric Evans in his seminal book on Domain Driven Design (DDD). It’s subtitled, “Tackling Complexity in the Heart of Software”. DDD is a comprehensive methodology for approaching the design of software, fully cognizant of the daunting reality of ever-evolving processes.
However, DDD addresses the development of operational systems, the systems that makes things go. DDD and other such development methodologies that grew from there tame the transactional (OLTP) side. But they don’t directly address the business intelligence (BI/OLAP) side concerned with analyzing the past for hints at how to affect the future.
At the time DDD first appeared (early 2000s), BI just passed its tipping point towards becoming a household term. In those early days, BI followed an ETL process. Data is first extracted from multiple sources. All sorts of transformations are applied to the data, taming it into an integrated, generalized, “conformed” star/snowflake schema. It’s finally loaded into a data warehouse and/or a small number of subject-oriented data marts.
The problem with traditional data warehouses is that reflecting the changes of enterprise operations require very much intense upfront work. Hammering out design issues for those hand-made “ETL packages” could span months, sometimes years. In the meantime, the analysts didn’t have access to new sources of data, so analytical activities and changes to reports had to wait.
Roughly around the same time, along came Dan Linstedt’s Data Vault Methodology V 1.0. This methodology enables the serialization of massive upfront work, delivering value to analysts from the beginning. As Figure 3 illustrates, a series of raw data deliveries can keep the analysts busy while cleansing and master data integration issues are hammered out between various parties with various interests.
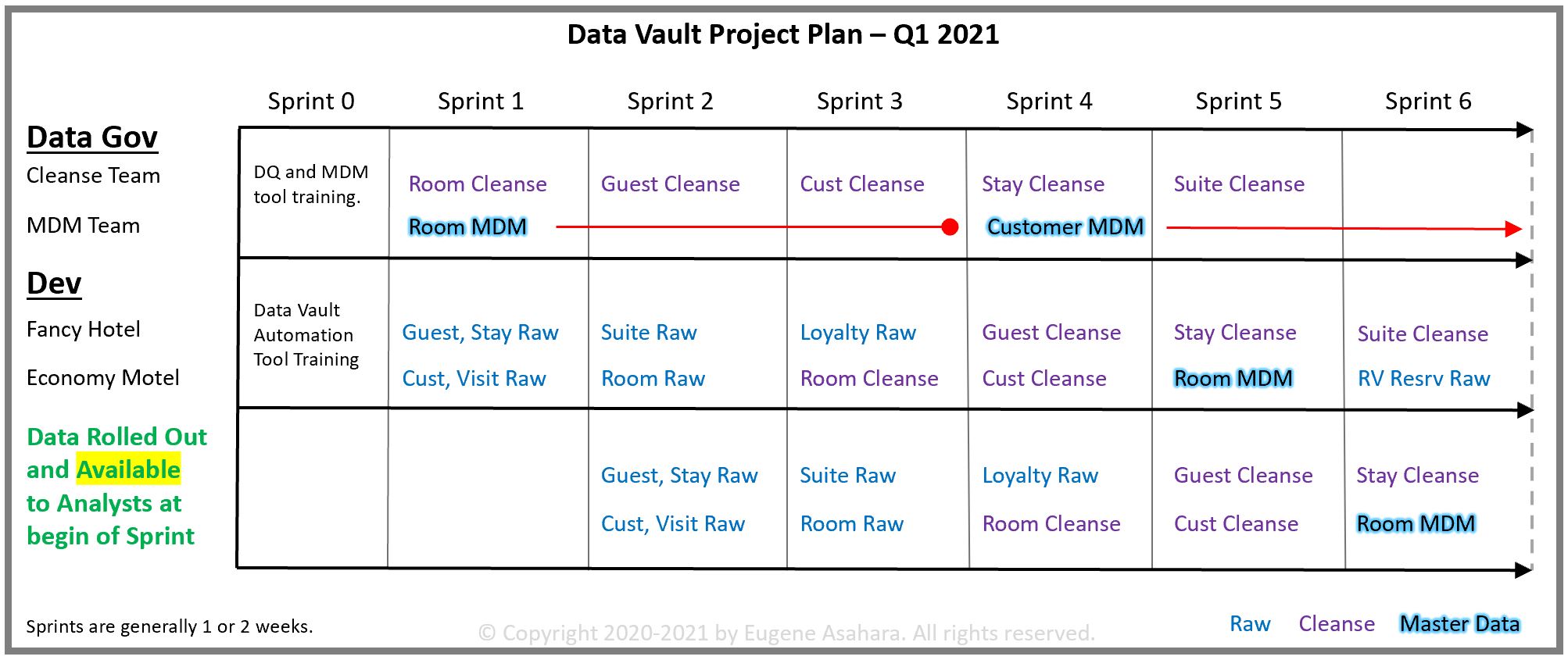
Although DDD and the DVM are two sides of the same coin, they are fundamentally different. DDD is of the OLTP world and DVM is of the OLAP world. OLTP is centered around distributed, transactional systems concerned with operations. OLAP is about integrating data across those distributed OLTP systems for strategic and tactical analytics. Their respective differences are very analogous to how most doctors differ from psychiatrists – most doctors deal with the body and psychiatrists deal with the brain and behavior.
The success of DDD and the DVM are both founded upon the daunting task of mapping out the massive web of relationships that comprise an enterprise which were never adequately captured and/or maintained over time. That inadequately documented messiness is referred to as a “big ball of mud” in the DDD lexicon. Like real mud, data systems are the results of decomposing order that can’t keep up with changes over time. That decomposition is exacerbated by resultant Band-Aid fixes.
Domain-Driven Design and the Data Vault Methodology
DDD is a set of very wise guidelines for designing systems that are as correct as possible and maintainable. It lies somewhere between friendly advice and strict dogma. Meaning, if it’s your guiding compass for software architecture, chances for success are greater. There is need for wriggle room since the real world of highly-competitive, fast-moving, information-overloaded, globalized business presents a mind-boggling space of possibilities.
On the other hand, DVM is a methodology that must be strictly adhered to. Inflexibility is more tolerable on the analytics side since the universe of analytics isn’t as expansive as the universe of all types of businesses. Analytics is sophisticated, but it’s confined to a well-defined world of metrics, statistics, correlations, and predictions.
The reward for adherence to the DVM is that it facilitates the automation of the drudge work of schema deployment, code development, and modifications using a tidy, comprehensive GUI tool. Less drudge work means developers are able to work on higher-value issues and removes opportunities for human error. The automation blends very well into DevOps paradigms.
Since the problem space of DDD covers a much vaster world (all the possible ways people can do business) than that of DVM, the design tools in the DDD world aren’t quite as helpful. If we’re building custom solutions, there are various UML tools for encoding design efforts. But again, it’s difficult to capture all the nuance required of a custom solution.
Alternatively, if we bought massive commercial software solutions covering major enterprise domains (ex: CRM, SCM, ERP), the bulk of the design is done for you. But these solutions are still supplemented with powerfully expressive human-composed code (Python, Java, C#, X++) or configured rules that handle the nuances of your enterprise.
However, the notion of encoding the design elements of DDD with a functional programming language has emerged over the past few years. In particular, Scott Wlaschin’s work applying F#, the functional programming language, to the DDD process is an incredibly compelling option. With very minimal acclimation, the design artifacts (actual F# code) are readable by developers, non-developers, and computers. That last one, computers, means that from the F# design code, much of the solution code and DevOps deployment tasks can be generated.
A primary message of this blog is that the combined work of Eric Evans (DDD), Dan Linstedt (DVM), and Scott Wlaschin (DDD with F#) addresses much more than the designing of OLTP and OLAP systems. It’s even more important to address the maintenance of these systems over the five to ten year expected life horizon of typical enterprise software.
Similar to the good intentions of New Year resolutions, we’ve all participated in festive project kickoffs, elaborate design sessions, and interviews by consultants where we ended up with a lot of UML (Unified Modeling Language), spreadsheets, and a tight PowerPoint presentation to the stakeholders. Software projects often start at this high level of order, but entropy quickly sets in.
Even before any Version 1.0, we discover things we missed, things we underestimated, or things we just got wrong. The deadline for V1 is punted out, or we “save that for the dot-five release”. After Version 1.0, over the years bugs expose themselves, rules change, customer appetites change, new strategies are implemented. The rate of entropy depends on whether we handle those changes in a disciplined or ad-hoc manner.
Entropy is drastically mitigated through:
- The code-based capture of the DDD design as a centralized map of the enterprise, where all changes should begin.
- The comprehensive automation tools of the DVM.
Here are links to the seminal works that are core to the theme of this blog:
- Domain-Driven Design: Tackling Complexity in the Heart of Software – Eric Evans.
- Building a Scalable Data Warehouse with Data Vault 2.0 – Dan Linstedt, Michael Olschimke.
- Domain Modeling Made Functional: Tackle Software Complexity with Domain-Driven Design and F# – Scott Wlaschin.
Hammering Square Pegs into Round Holes – Primary Use Case
A major way that enterprises evolve is through mergers and acquisitions. M&A isn’t like simply adding another Lego piece to the sculpture. Systems must be connected, processes merged or linked, and data consolidated into an enterprise-wide view. But it’s always harder than we imagine.
An extreme of M&A turmoil is experienced by conglomerates. During my business travels, I was always intrigued by how the Marriott or Hilton Garden Inn I was staying at is actually owned by a corporation (not Marriott or Hilton) that is a conglomerate of franchises. Some are rather homogenous, like a collection of McDonalds. Some are very heterogeneous, a mix of various types of businesses, in different environments, different service levels.
The heterogeneous sort of conglomerate has an interesting problem of trying to integrate the franchises into a consolidated enterprise view. Each acquired restaurant, hotel, and car lube franchise in these conglomerates could differ in more ways than being different business types. There could be many brands of restaurants and hotels that must use their brand’s system or held to brand regulations. They could operate in different states or even countries, each with unique local laws, local preferences, and local conditions (such as the presence of a strong competitor).
Figure 4 illustrates two conglomerates attempting to generalize and forge two conglomerates into one. Each franchise is different and resists conforming to a one-size-fits all structure. This hammering of squares into round holes is done in the name of minimizing IT costs and complexity.

For some types of conglomerates the acquired companies could contrast even more substantially than a Marriott versus a Hilton. For example, if a conglomerate acquired a Morton’s Steakhouse and a McDonalds, they are both about food service, but operate under very different business models. It would be difficult to force a single system on them without sacrificing the ability for them to perform to their fullest potentials. How could a Morton’s operate under a system meant to also accommodate a McDonalds?
However, the conglomerate must still integrate data from each to provide executives with a current enterprise-wide view of what’s going on. OK, so we develop ETL packages dumping data into for the Morton’s and McDonalds into a single DW.
But what if a food truck were added? It’s again a very different business model. Then later, we acquire a catering service? It will quickly become nearly impossible to shove more types of data into that centralized DW without great sacrifice of time and resources and without breaking something else for everything we fix.
In fact, all businesses are conglomerates of a sort, not just these sort of franchise conglomerates. All businesses are an aggregation of heterogenous departments. Each of these departments is like an organ in our body with a special function. The result of the interaction of the departments or organs is a productive and thriving business or person, respectively.
Each of these departments performs well-defined functions and are staffed by personnel with particular knowledge, skills, and lingo peculiar to their profession. The departments are interested in particular sets of attributes of the various entities or things they work with.
Figure 5 illustrates how IT is serving at least three competing needs as well as attempting to keep itself a lean, mean, IT machine. These competing needs result in years-long efforts to fully assimilate acquisitions.
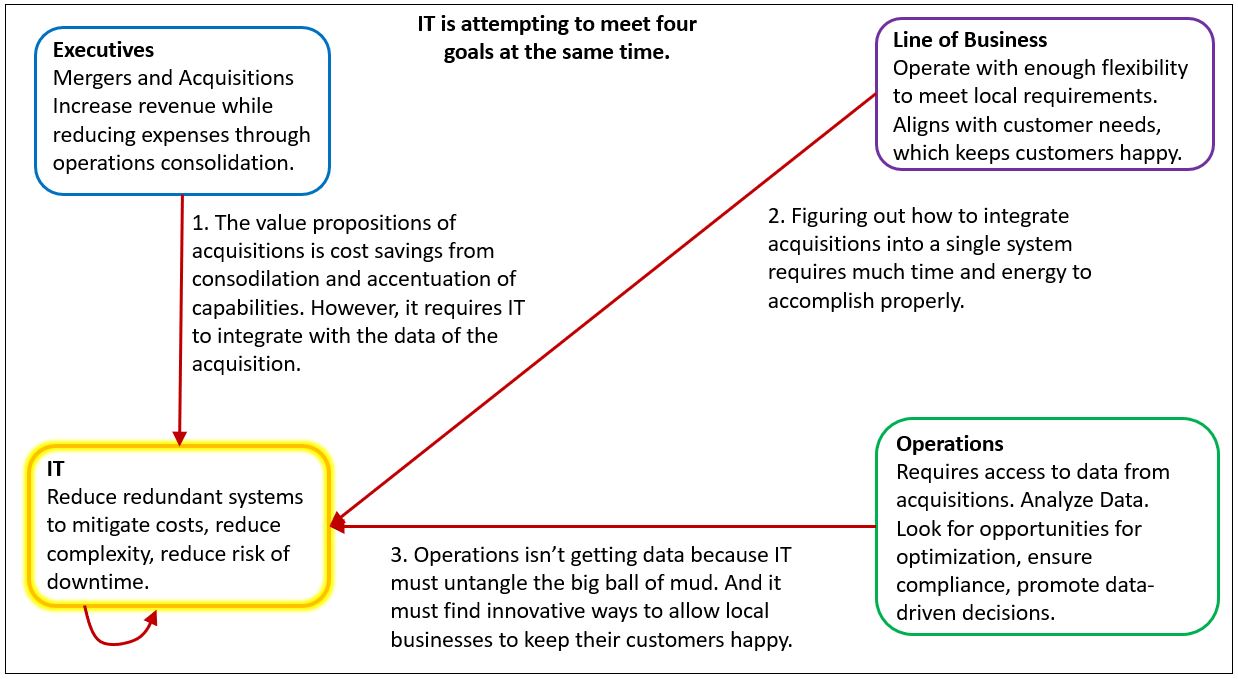
So arguments, misunderstandings, and impasses go on and on. Before you know it, the project deadline has passed, maybe even years. What if we instead backed off from providing nothing but the perfect solution and first provide relief to analysts with raw data and iteratively usher in integration and change?
Domain Driven Design
The main idea of DDD is to untangle the monolithic web of all that goes on in your business and organize it into a set of loosely-coupled functions. That set of loosely-coupled functions facilitates development of systems that serve your business’ continuously evolving needs with as little friction as possible.
A “domain” is your business. That includes the processes, the motivations, the rules, the interactions with outside entities, the capabilities of people and machines, the terminology, and as many of the knowable things that could go wrong. All of these things interact in a web of relationships that somehow, through all the chaos, still produce products of value to customers.
DDD is a business-first process to comprehensively map it all out. I’ll soon describe how the process begins with an activity called Event Storming and ends with a product, a map, called a Domain Model. The domain model is really the core of this blog and it’s the primary link between DDD and DVM.
However, although the business will be comprehensively mapped out, it should be done in an iterative manner. It’s not the idea to “boil the ocean in one big bang”. The idea is to map out what’s needed to meet the business’ requirements so that it can be built once, not twice.
Figure 6 is a very simple domain model of a single restaurant. It’s an untangling of how processes and skillsets interact with each other. We see a few bounded contexts grouping by solutions. For example, the processes of the kitchen is very different from the processes of the dining areas. We also see the domain of cooking food, which is a different skill set from dishwashing. But the process of a kitchen involves both.

Usually, the Domain Model consists of sets of “dead” documents – UML, spreadsheets, PowerPoint, etc. But later, I’ll introduce how marrying DDD with functional programming results in a domain model in a more animated format. A format of genuine code that is understood by computer programs and people (which does include developers).
Such an enterprise-wide map of the relationships, understandable by all, opens the possibility of a practical single source of the truth. Ultimately, the idea would be for this domain model to be the starting point of addressing changes or fixes in the enterprise. The same way we (used to) first consult a map before heading out on a journey and how we would ensure the map is up-to-date faithfully reflecting the “topology” of the the area of our travel.
Here are a few definitions that will be used over the course of this blog. These definitions are by no means complete. But it should be enough to get you started and carry you through the rest of the blog.
- Ubiquitous Language – The jargon/lingo spoken by the people who actually perform the work we’re modeling.
- Domain – Business capability such as HR, sales, manufacturing. It’s usually a hierarchy of domains and sub-domains. For example, within HR would be payroll and recruiting. It’s said that a domain is a problem space and the bounded context is the solution space.
- Bounded Context – Bounded contexts can span multiple domains. What generally defines a bounded context is the presence of a common language and a well-defined business capability. Figure 6 shows Accounting, Food Preparation, and Serving. We can think of the Serving bounded context as a cross-functional team of hosts, servers, and bussing folks.
- Big Ball of Mud – Software made up of tightly coupled components. We can’t untangle the software into discrete, loosely-coupled services.
- Context Mapping – Domains and/or Bounded Contexts interact with each other. Interacting through these interfaces is what maintains the integrity of a the untangled big ball of mud. These are actual components from which two bounded contexts communicate. Translations of logic and transformations of data between domains or bounded contexts are maintained here.
- Anti-corruption Layer – A fully-fledged component that sits between one or more domains or bounded contexts. All communication goes through this component so rules are consistent and centralized. It’s like a third-party interpreter between people speaking different languages.
A big clue that DDD is the most sensible approach to software development is that it fits so well with other disciplines, such as event storming, microservices, functional programming, and event sourcing. I touch on event storming and microservices later, but will leave event sourcing for another blog.
There are a large number of very good videos and references for Domain Driven Design, but here are my selected ones to start with:
- What is DDD? – Eric Evans – This one-hour video, by the founder of DDD himself, is a good introduction to the concepts. I haven’t been able to find a shorter one, but with sincere respect, it works at 1.5x speed 🙂
- Domain Driven Design: The Good Parts – Jimmy Bogard. I can’t find an adequately good short video introducing DDD. But this one-hour video is an easily digestible (and rather entertaining) introduction to a DDD use case.
- Bounded Contexts – Cyrille Martraire. I think bounded contexts is the most important concept of DDD. It subsumes other fundamental DDD concepts such as ubiquitous language.
Data Vault Methodology
The Data Vault Methodology is the recipe for the implementation of an analytics database that is more robust than the traditional star/snowflake data warehouse. As depicted in Figure 7, data vaults lie somewhere between the chaos and anarchy of an unstructured data lake and the rigidity of a highly transformed star schema.
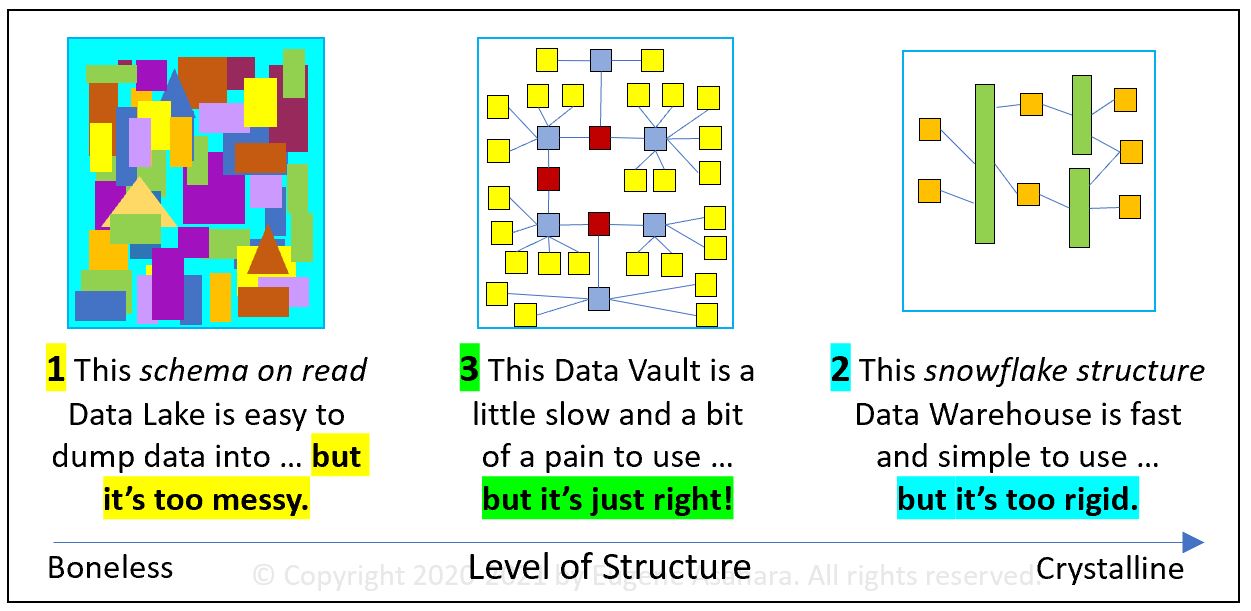
As it is for traditional data warehouses, the source data for data vaults is generally one or more relational databases. Data sources could be SQL Server, Oracle, Snowflake, Redshift, or some NoSQL database with a SQL layer such as Hive over Hadoop or Databricks’ SparkSQL over a Delta Lake. Because this blog is in large part about linking DVM to DDD, and in turn DDD is linked to microservices, in the topic, DVM and the Domain Model, the data source possibilities include microservices.
The key benefit of a data vault is facilitating a high level of iterative improvement. This is primarily accomplished through a data schema normalized beyond that of a star/snowflake schema made up of dimensions and fact tables. DV schemas are more “normalized”. They consist of hubs, which represent entities, satellites of the hubs, which are groups of attributes about the entity, and links, which relate entities. That not-too-loose/not-to-strict level of structure is a sweet spot that provides enough freedom to capture a wide variety of databases but not so much so we are hammering square pegs into round holes, as previously discussed.
Figure 8 depicts a fragment of a data vault schema for visits from two data sources: Fancy Stay Hotel and Economy Motel:
- The blue squares represent hub tables. Hubs are generalized entities. For example, a customer could be a patient, member, visitor.
- The yellow boxes are satellite tables. Each is a family of columns grouped by function, data source, or applied transformations.
- The red box represents a link table linking linking visits with customers and rooms.

Figure 9 is a close-up of how Link, Hub, and Satellite tables relate to each other as well as depicting the columns that are part of the DVM.
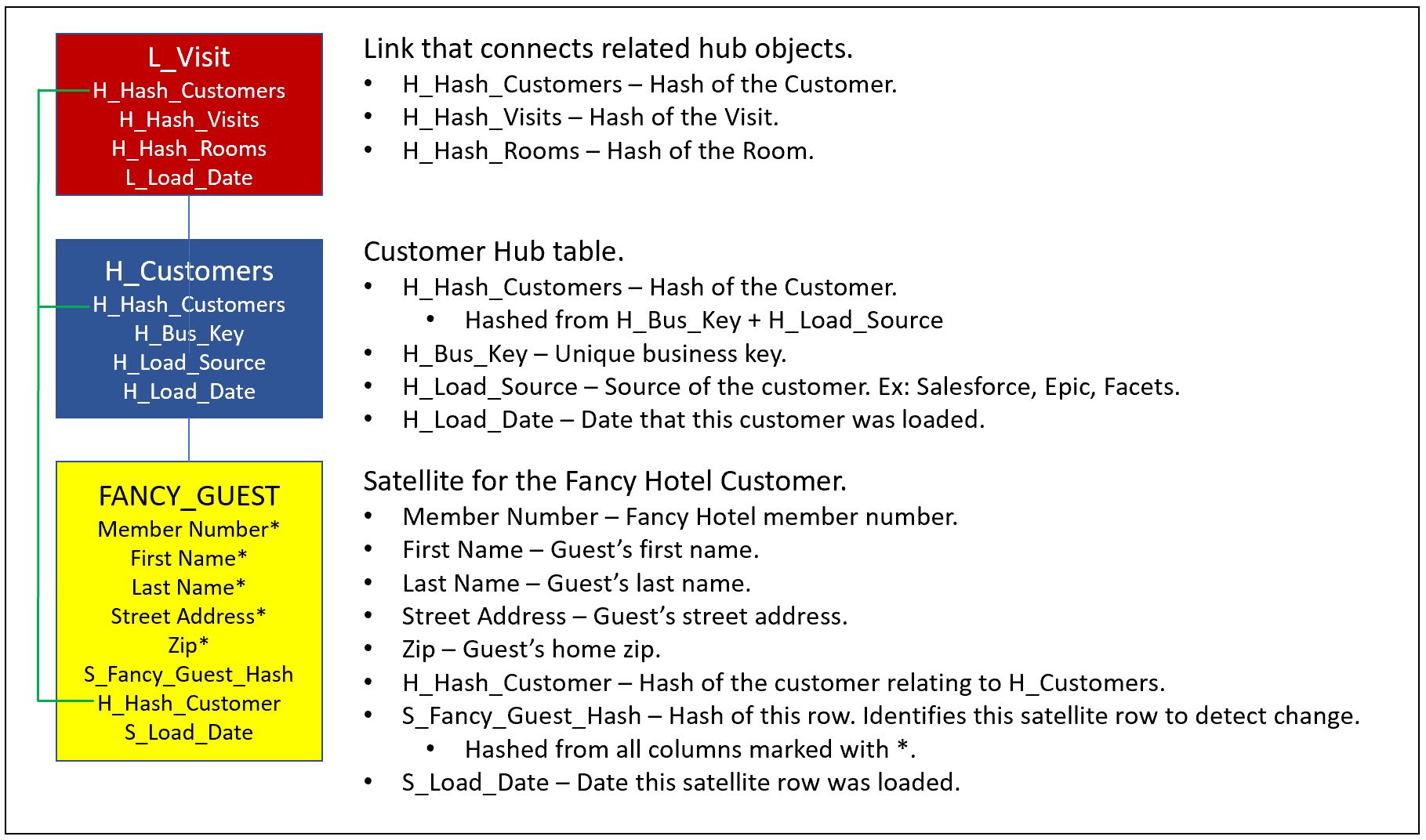
Because DV schemas are more complicated than traditional star/snowflake DWs, that complication is mitigated by configuring, deploying, and managing through specialized software. This is possible because the Data Vault Methodology is a set of stringent rules. Stringent rules means it’s highly automatable. This automation opens the door to BI systems manageable to a high level of efficiency in a DevOps fashion.
Data is extracted and loaded into a Raw Data Vault in its raw format. This means we maintain a record of the data as it was made, without any transforms. All data changes are recorded. In DW terms, all entities are Type 2 slowly-changing dimensions. This enables:
- Time travel – the ability to reconstruct the state of the database at some given point.
- Auditability – Raw and historic data are the basis for growing auditability demands.
- Context – Your data when you lived in CA isn’t counted in your current state of HI.
The raw data can then be transformed downstream in many ways into various types of repositories such as a Business Vault, Data Marts, or OLAP cubes. Configuration of these transformations through the data vault tool facilitates traceability, which we’ll discuss soon.
Transformation of raw data from the data vault into other forms suggests that although Figure 7 compares an unstructured data lake, data vault, and data warehouse, they are not exclusive options. The three are implemented in various combinations ranging from just a data lake to all three.
For example, using all three, Data Lake, Data Vault, traditional star DW, the data lake could store data not yet modeled into the data vault, and one or more data marts (mini subsets of a traditional DW) could be derived from the data vault for performance optimization.
Lastly, please note that DVM is more than just the data structure. It is a methodology which promotes common approaches, prescriptions (such as methods for parallelization of loading), and language (like the benefit of DDD’s ubiquitous language).
Here are a couple of videos for more of a feel for the Data Vault Methodology:
- How to create a Data Vault Model – Dani Schnider. This is one of the best short videos on any technical topic.
- A Brief Introduction to Data Vault – Excellent 7-part series of short videos introducing Data Vault 2.0.
- Data Vault vs Data Lake: Are they different, similar, or synergistic – An easily digestible 20-minute video with a title that explains itself very well.
Why a DV and not a Traditional DW?
A Data Vault is a type of data warehouse. At least for old-timers like me, by “data warehouse” we’re used to the traditional data warehouse (TDW) composed of a number of star/snowflake schemas. The Data Vault is considered to be an advancement over the traditional star schema DW.
The key benefit of a DV over a traditional DW is that the DV facilitates the serialization of the substantial amount of upfront design and development that’s usually required before new data sources are made available for analysis. In practical terms, analysts will have access to new data sources quickly, as opposed to when it’s “perfect” (if ever). Discrete steps towards “perfection” can be easily planned and implemented in an iterative, agile manner.
For example, a DV can begin with just a customer hub with just one satellite holding raw data from one data source. That can be set up with the data vault configuration tool in a minute and provide value (albeit limited) as soon as it takes to import the data. Thereafter, there are many possible iterations such that can easily fit in two-week agile sprints. For example:
- A raw customer satellite from another data source.
- Another hub and satellite for products from one data source.
- A cleansed version of the original raw customer satellite.
- A satellite that is a mapping of the two cleansed customer satellites.
- Another microservice resulting in satellites for one or more hubs.
ETL vs ELT
Data presented to end-users from a traditional DW, or usually presented to a DV, is the product of very much transformation. The difference is the stage where the transformations are performed. TDWs are implemented with old-school ETL, where:
- Data is Extracted from a number of enterprise data sources into a staging area. The extraction of new and/or changed is designed to hit these operational source databases as little as possible.
- A number of Transformations are performed on the data – mapping, cleansing, calculations, etc. Transformation is the toughest part. More detail below.
- Finally, transformed data is Loaded into the Data Warehouse for consumption by business users.
The big problem with the old ETL method is the lengthy and tedious process of hammering the design of all the transformation rules. Coding up the ETL packages and schema changes is the relatively easy part. It’s no exaggeration to say that upfront work can take months before new data sources to be correctly implemented into the data warehouse.
ELT, popularized by data lakes, takes a different approach of extracting and loading source data into some sort of massive data lake. The data sources are impacted once for each set of new data and immediately dumped. and all the data is in a centralized place. There is very much value in having data readily accessible from a single place, even if the data is raw and still needs work.
From that central source, many clients (business analysts, data scientists) are free to analyze the data and apply their specific transformations, unencumbered by the needs of other parties. Extract once, load into a data lake, and transform many times.
When data lakes first appeared over a decade ago, the well beaten mantra was, “Storage is cheap and data lakes are ‘infinitely scalable’, so let’s just dump everything into a data lake. If it turns out to be of value, it’s there and accessible, somehow or another. If it’s worthless, who cares, storage is cheap.”
A Data Vault fits well into the ELT process. New Data source data is extracted and dumped right into the Data Vault, raw. In fact, that data vault is called the Raw Data Vault. Figure 10 shows the current ETL path and the newer ELT path. The two main points are highlighted:
- The problem of lengthy upfront work of the ETL path.
- The benefit of many transformations from raw data of the ELT path.

The difference between the ELT of the data lake and the ELT of the Data Vault is that the data vault has some structure. As mentioned above, with more structure than a data lake but less than a traditional DW, a data vault sits between the total anarchy of an unstructured data lake and the stifling bureaucracy of a traditional DW.
Metadata-driven Automation and Traceability
One of the critical, recurring IT support problems submitted by end-users is validation of what the data represents, how it was calculated. It’s great that end-users question data. The problem is that their question can sometimes take days to weeks to answer, consuming dozens of hours of IT time.
Even grizzled, old data engineers like me struggle to wade through the web of cube definitions, data warehouse schemas, views, stored procedures, and SSIS packages to figure out how “Net Profit” is calculated. There still exists a great number of traditional DWs that have been in service a decade or more, before data warehouse configuration tools (ex: TimeXtender) became commonplace. So these old DWs are still maintained by hand, still not catalogued and readily searchable by a metadata management tool.
Because a DV is more complicated than a traditional DW, configuration, coding, deploying, and maintenance through automation software is pretty much an immediate necessity. So traceability of the lineage of data is a natural benefit of a data vault. More on these configuration tools later.
Transformation Patterns
The purpose of a data vault starts with the ability to store all the data needed for analysis, in its raw, unadulterated state, along with its full history, in a single place with some level of structure. Thereafter, in order to foster the traceability benefits of the Data Vault, downstream transforms from the raw data vault should be based solely on data in the Data Vault. Data transform lineage can be traced back to the raw data.
In order to promote the programmatic viability of implementing downstream transforms, there exists clear patterns highly conducive to programmatic transformation. Examples include:
- Point in Time (PIT) – These transformations are snapshots of a satellite table at a point in time. They exist as just another satellite. In traditional star/snowflake terms, this is can be a dimension table. However, it probably doesn’t include master data generalization.
- Same as – A satellite that maps keys. This would be like a master data management table.
- Bridge – A view that collects events belonging to the same object. For example, a hotel booking involves microservices for the initial booking, check-in, payment, check-out. Each event exists as a separate, raw, event satellite. These events will be consolidated into a single booking satellite. This is star/snowflake schema fact table.
The Domain Model
The Domain Model is the primary product of a DDD process. It’s a model of an enterprise that should be sufficiently understandable by everyone involved in a software development project. “Everyone” is a highly diverse set of entities that includes programmers, project managers, business users (the people who actually do the work in the enterprise), executives, architects, and whatever subject matter experts.
I became interested in the notion of a broadly comprehensible domain model soon after I started my first Data Vault project. What was quickly evident is that I still needed a comprehensive enterprise map to help determine the prioritization of data into the DVM and how it all related. It turned out that the process of exploring flow and what is important for analytics looked like the DDD process of building a domain model.
I need to clarify the definition of Domain Model for this blog. I refer to it as a “model of an enterprise”, which is too lofty in reality. A “domain model” is literally a model of a domain. However, enterprises are made up of a number of domains. It’s also short-sighted to build a software system with thick boxes drawn around these domains as if they as if they operate in a vacuum.
So what I’m referring to as a Domain Model is a model that is intended as a map of the enterprise. It’s really a collection of the little domain models and how they interface with each other. There may be mysterious areas here and there, but we mark it as such, a big ball of mud.
Currently, domain models usually take the form of a set of UML, at best. At worst, it’s a bunch of unstructured Word documents and Excel spreadsheets. However, in the last topic of this section, DDD and Functional Programming, we’ll explore how encoding domain models using a functional programming language makes it readily consumable by computer programs as well as people. In fact, that broadly readable domain model is key to bridging DDD and DVM.
Further, a data vault is about implementing change with as little friction as possible. Frictionless implementation of change is a goal of the domain model too. As a mirror reflects changes in our facial expression, the domain model should continue to reflect the changes to our business.
A domain model naturally documents what is actually used. That’s important because it’s impractical to include every single table in every single data source. It’s nice to think that all data could be important, but we’re talking about what could be tens of thousands of tables comprised of hundreds of thousands of columns scattered throughout an enterprise.
The domain model lays out all of the processes and what is involved with those processes. Because a primary goal of analytics is to identify how and where we can optimize operations, we know the data that is relevant. And that data should be readily available to analysts looking for strategies to optimize as well as to those who are doing the work.
On the other hand, limiting what we base our analysis on to what we know is relevant results in narrow-mindedness. Because the DVM is about embracing change, when we have a suspicion that some piece of data could shed insight, we can easily add it to the data vault.
Before continuing, I need to clarify a couple of things. The first is that a “Domain Model” may not be a single, complete, uber-model. It may consist of a few pieces. Like an “atlas of the world” hundreds of years ago, there were many gaps. Those fragments still comprised a “single map”, just with holes. Those holes are analogous to what a big ball of mud in a domain model.
Second, the substantial upfront effort to build a domain model contradicts one of the principle benefits of a data vault. That is, facilitating the serialization of massive upfront work into bite-sized iterations. So choose your poison: upfront hammering out of cleansing, integration, and master data issues or building a domain model.
Data Vaults have been built for over a decade without first creating a domain model. The data vault automation tool only needs to read the schemas of databases. The big deal is the “ordeal” of building domain models not only untangles enterprise complexity, but it’s also the foundation for true knowledge management. That’s something useful for data vault developers and any sort of new member of the “tribe”.
Tribal Knowledge – Enterprise Documentation Stuck in Heads
At one time a smart observation was that most of the data resides in Excel spreadsheets on laptops all over the place. But I tend to think that there’s much more data than that stuck in the heads of the employees. It grew and evolved over tens of thousands of hours of service to the enterprise. And it leaves with them when they leave. We’ve all seen it many times.
That tribal knowledge is of a much richer nature than the descriptive data in a database. It holds human-grade intelligence of context-filled knowledge/wisdom of how things happen, with what, where, and maybe even why.
When I start on a project, I ask for any documentation to help me get up to speed. I’m told there’s very little, it’s outdated, low in quality, and that they hoped I would produce it since that’s a good way to learn. Sometimes there’s a data catalog, but it usually contains just high level information with usually no information about how columns relate. There is usually a pretty good user’s guide, but then there isn’t much documentation of the software implementation.
Why doesn’t adequate documentation exist? Simply because it’s very hard to produce, sometimes harder than coding itself, and a lot harder to maintain. There’s a never-ending queue of crises, and for each crisis, it’s easier to just somehow deal with the crisis. But yet, things somehow work out – because of the human tribal knowledge that’s readily available, until it some day isn’t.
It’s hard to see the pain when the gash somehow miraculously “self-heals” by the IT fairies, so the value of investing into documentation and its maintenance takes a seat far behind bugs and critical changes.
The immensely worthwhile value of a Domain Model produced from a DDD process is that it would be the unicorn documentation I ask for when I start a new project. It is the anatomy of the enterprise, the recipes of the processes, and the enterprise’s laws of physics.
Somehow, though, enterprises successfully operate without a properly maintained domain model. That’s because there actually is a domain model. It’s just that much of it, if not most of it, is stuck in peoples’ heads.
Reliance on tribal knowledge as the documentation of enterprise processes is risky and expensive. So why is it so prevalent? I think it’s because we have no choice but to make things work and it’s easy to forget how hard it was to solve a problem when another rises immediately to the top of the todo list.
As shocking as it may be for an enterprise to lose key personnel, life goes on. Like any wound, the gaping hole left in the enterprise eventually rewires. The healed wound may result in something not quite as good as before, or maybe better, but most likely different. Some opportunities were lost during the healing process, but hopefully something was learned and new doors were opened.
Event Storming
One of the most highly effective methodologies for starting a DDD process is with a hurricane of an approach appropriately called event storming. The idea is to expose all issues in the context of a software project upfront in order to to avoid those big surprises that pop up halfway through development.
This is accomplished by gathering people from all aspects of the business and the solution project into the same room. That includes business owners, architects, programmers, project managers, testers, documenters, and stakeholders. We should ensure that all that tribal knowledge trapped in human heads is represented. Strictly speaking, that can mean everyone.
Of course, for a large corporation, tens of thousands of people can’t be collected and shoved into a room to hash out how things work. But there should be representatives of folks who actually do the work out in the field today. Even though managers may have been promoted “from the field”, things change, and so there’s often some level of disconnect between theory and reality that probably will spring a big surprise when it’s too late.
The walls of that room where participants are gathered should be a blank canvas upon which hundreds of post-it notes will be stuck.
An Event Storming session certainly sounds like a horrible time. And most have probably been through some similar exercise, only for it to end up having been a waste of time. But if the DDD process is followed through, software is actually built, and the software is maintained forever from the domain model, a shindig of that magnitude should be a once in a decade or more event.
The first phase is for all those varied folks to just write down all the events that they can think of. They don’t care if someone else will come up with the same events. That will be dealt with later. When we’re satisfied that all events have been listed, we have a catalog of the enterprise. This “events-first” methodology is the reversal of how we usually first identify the things that are involved in the enterprise then figure out how they relate.
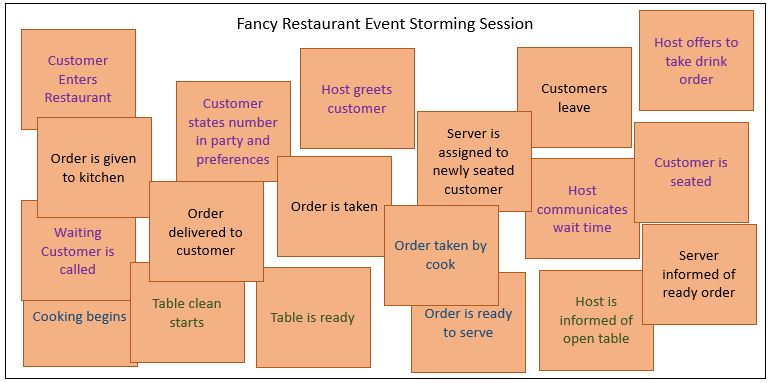
Driven by decades of object-oriented programming, we instinctively want to begin by identifying the entities. But starting with events, followed by entities/things involved with the events, then the interactions between entities, we stand a better chance of having painted a full, integrated, and kind of dynamic picture of the enterprise processes.
For those familiar with star/snowflake schemas, these events are sort of like “facts” (transactions), but facts are sometimes more like transactions consisting of a chain of related events. For example, a sales fact table may have a purchase date, ship date, and receive date – all three of which are events where something could go wrong.
When we’re comfortable we’ve brainstormed all events, the next step is to rearrange the events into the sequence of what happens. We can remove duplicates at this time as well – as long as we’re sure there aren’t subtle but important differences. When we have the sequence in place, all the people who actually do the work can look at the parts they are involved with, think about it, and say, “Yeah, that’s exactly how it all goes!” Or … “I don’t know what Universe you live in, but that’s not how it goes in mine!”
After we’ve identified and sequenced the events, we can fill in the inputs and outputs of these events. These inputs and outputs are attributes of some entity, which we can now label – customers, dates, products. For the traditional DW folks, these are pretty much the dimensions.
The end product is usually a set of Sequence UML diagrams. However, in the next topic I cover how these events could be captured in a functional programming language. Sequence UML could be generated from that code for a more human-friendly view.

From the analytics point of view, the value of the sequence diagram is it points out exactly where transitions are made, what and how much goes in, and what and how much comes out. From this we know where the opportunities for optimization are. We know where to place metrics. How long did it take? Did we get back what we put in? Are results unexpected – meaning something in the real world has changed and we need to investigate?
In the next topic, we’ll see how the events-first paradigm of event storming fits very nicely with the functional programming approach of encoding the events. Events are the result of some process that took in a set of things, something happens to or with those things, and there is a result.
Here are selected videos on Event Storming:
- Event Storming Demo & Discussion – This is an excellent 48-minute demo of an event storming session.
- Event Storming – Alberto Brandolini.
- How to Make a UML Sequence Diagram – LucidChart – A nice 8 minute video on the basics of sequence diagrams.
DDD and Functional Programming
The rise of functional programming (FP) over the past few years is a game-changer for software development in general. FP adds a profound dimension to the potential scope of DDD’s benefits. Functional programming blends in very well with the notion of events-first approach to domain modeling. This is the secret sauce that breaks open the gate for DDD.
It used to be that UML diagrams were static, dead, artifacts created during the conceptual and planning phase, and never to be seen again once the developers opened Visual Studio. In truth, UML encoded with PlantUML is code. But it is a limited, domain-specific language. A fully-fledged functional programming language is much less likely to run into a logical wall.
But if we could encode the domain model in such a way that computers could understand it, we have code as documentation. Actual code as documentation enables a significant closing of that chasm between human brains and computer systems. The key is that this code as documentation must be readily understandable by programmers, non-programmers, and computers (particularly DevOps systems).
Figure 13 depicts the current method for non-programmers and programmers to hash it all out versus the code as documentation way. Currently, human programmers and non-programmers haphazardly collect and sort out requirements, recording it all in mostly unstructured formats. The programmers then go off to their corners to program until integration testing time.
The code as documentation way shows programmers and non-programmers working from a domain model written with F#. When everyone is satisfied that the model reflects what really happens, the programmers fill in the blanks. The nature of the strongly-typed model is that unit testing is naturally built in.

The syntax of functional programming languages involved in the DDD process is relatively easy to understand. In particular, the syntax of types and functions. Even non-programmers can easily get the gist of what’s going on. I find this to be true particularly for F#.
For example, although the sequence diagram in Figure 12 from the previous topic is probably more readily understandable by everyone involved in the project than F# code, the information captured in the F# code shown in Figures 14 and 15 is still well within average human comprehension.
In Figure 14, it’s F# code, but it’s easy to see this describes some of the things involved with our Fancy Restaurant. For example, there is something called a Server with a ServerID and a name of a person. In turn, the name of a person has a first name, last name, and nick name. With this information, we can also tell that by “server” we’re referring to the person who takes your food order and brings it to you – not a computer running your solution.

Figure 15 shows a couple of functions. In other words, something that happens. Each of those functions defines the inputs (the stuff within the first set of parentheses) and the output (the stuff in the second set of parentheses). For example, requestTable is the event where the host queries the bus person on the availability of a table. The host gives the bus person the number of people in the party and the type of table (table or booth), and the bus person returns the name of a table/booth that can sit that number of people.

Notice the pair of curly braces at the end of the requestTable line in Figure 15? That’s where the logic of selecting a station is placed. That logic could involve other functions.
The approach of capturing domain models with a functional programming language leverages the advantages of them. For example, the strongly-typed and immutable nature of functional programming languages objects greatly reduces the risk for bugs resulting from unexpected usage.
The function definitions provide a methodology for capturing business rules in the single place. F# types and functions are also very accessible as just another .NET library through C# where the types and functions could be used in object-oriented code.
The power of such a design document means that it is capable of taking the place as the single source of truth, as far as rules and processes are concerned. For example, when a change in process is required, the domain model is first modified to reflect the business, and changes are propagated from it.
With a code-based Domain Model, it becomes more than a document, but it becomes the center of operational truth. If we missed something or something changes, we update the model and alert the programmers of the need for the change. The code change must reflect the model – as opposed to changing the code and ultimately forgetting to update the model.
The combo of the code-based domain model on the DDD side and the Data Vault configuration tool is a powerful metadata management system. Here are my favorite videos on the subject, which I wish existed when I was first learning DDD and FP:
- Domain Modeling Made Functional – Scott Wlaschin – Always entertaining, Scott Wlaschin is the pioneer of combining DDD and FP. Of all the videos I’ve listed in this blog, this is the most important.
- Functional Programming and Domain-Driven Design – a Match Made in Heaven – Marco Emrich – This is more focused on DDD/FP as a concept, as opposed to Scott Wlaschin’s which is more on F#.
- Functional and Algebraic Domain Modeling – Debasish Ghosh. This is a great 40-minute video laying out the concept. It might be slightly mathy for some, but it’s one of those that I think is worth watching a few times until you get it.
- The Functional Programmer’s Toolkit – Scott Wlashchin – This is an excellent follow-up to Udi Dahan’s videos just above. You’ll see many of the connections between DDD and FP. This video pairs well with one on microservices that I recommend in the next section, Finding Services Boundaries, Udi Dahan.
- Diagram as Code – Using VS Code and PlantUML – Azure DevOps Tips – An 11 minute video on programmatically creating UML with Visual Code and PlantUML.
- (Added 11/23/2021) Domain Driven Design Patterns in Python – I was very pleased to see this!
DVM and the Domain Model
Since the domain model is a comprehensive map of the workings of the enterprise (the OLTP side of things) and the data vault is optimized for analytics (the OLAP side of things), the data schemas will be organized very differently. So how does the domain model help with DVM?
To start, from the domain model, we see what data is actually used in the enterprise processes. This is important since I’ve worked at enterprises where the number of tables across all systems numbers in the tens of thousands and the number of columns is in the hundreds of thousands. As scalable as a DV may be, and even with automation tools, modeling that many tables into the DV is more than daunting. So as it is with a traditional DW, we try to bring in data on an as-needed basis.
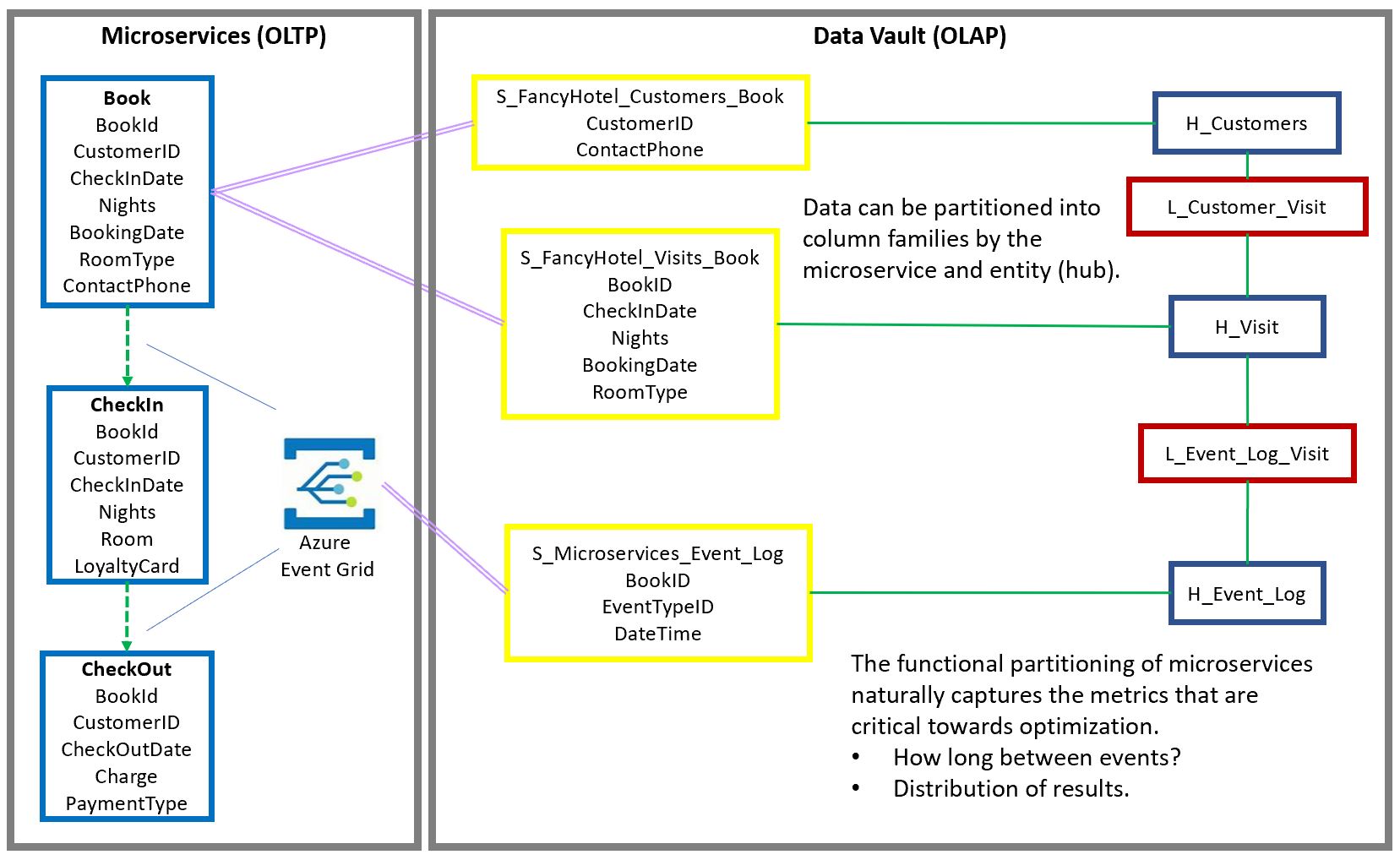
Figure 16 shows a sample of how OLTP-side microservices could be mapped into an OLAP-side data vault.
We can see that the satellites on the Data Vault side are partitioned by the microservice and entity (hub). It’s a nice way to organize data, as a column family. Data on the OLTP side is generally stored in row format. Conversely, data stored on the OLAP side would generally be stored in a columnar format. This column-family segmentation further enhances the ability to minimize data read.

The domain model also shows us what data is used together. For example, a service that validates a credit card needs the cardholder’s name, the card number, expiration month/year, and CVV number. That information comes in handy with helping to model the satellites. Since we know that data is used together, those four fields should be placed together in a satellite under the Credit Cards hub.
Figure 17 illustrates mapping of two boundary contexts, one a big ball of mud, into a data vault format.

Note the “Book” microservice in Figure 17. It contains data for the customer and parameters of the booking. The domain model provides the information required to split the customer and visit data into two satellites. This way, data that belongs together is stored and retrieved together.
Figure 18 illustrates that from an analytics point of view, the microservices decomposed as functions provides a convenient analytics map. It’s what goes on between the steps that is the basis for analytics. For example, How long between the steps? How often did the process terminate pre-maturely?
The domain model specifies how bounded contexts interface through the context mappings. This information includes mapping terms from the separate ubiquitous languages. This mapping information is useful in terms of Master Data Management.
- Finding your Service Boundaries – A Practical Guide – Adam Ralph – A great 57 minute video demonstrating how to decompose a domain into service boundaries.
- Finding Service Boundaries (similar title to the one above) and Microservices and Rules Engines – Udi Dahan – A very excellent pair of one-hour videos laying out the fundamental concepts of microservices and how the autonomous and event-driven nature of SOA (or microservices) fits in with the event-first nature of functional programming.
Data Vault Implementation Issues
Data Vault Data Platform
Since Data Vault schemas are more normalized than star/snowflake schemas, they are more complicated. There are many more tables involved, keys of various types, views. But this doesn’t mean Data Vaults are restricted to old-school relational databases like SQL Server and Oracle. Fortunately, there are very good Cloud options that behave in a relational manner – meaning we talk to it with SQL.
In particular, Snowflake is an excellent Cloud option for Data Vaults. Snowflake is best for option for use cases where data volume is massive and there is a wide variety of data. It handles Big Data scale data very well and is relatively good with updating (good for a scale-out Cloud database).
- Why Snowflake’s latest features are great for Data Vault – Dmitry Yaroshenko and Kent Graziano.
AWS Redshift is another good Cloud option since it too is a relational database.
Deploying a data vault simply on Cloud storage (such as AWS S3 and Azure Data Lake Storage) is tricky since data updates to the data vault involves updating a newer version of a row to active. That is, there could be many updates which probably affect many files (partitions). Again, it’s tricky – which is why Snowflake is the best option, since Snowflake worked through the magic to make it work.
For enterprises where data volume is on the smaller side by Cloud standards (up to a TB or two) and the variety of data is relatively low, SQL Server (on-prem or Azure) and Oracle are fine options.
Data Vaults can be quite large because of the wide variety of data and its full history. However, there are many cases where data volume (by Cloud standards) isn’t as much of an issue as is variety. In these cases, the size of the DV could be within a size that’s comfortable to a somewhat standard Cloud-based relational database. For example, Azure SQL DB with its 4 TB limit.
Data Vault Automation Tool
WhereScape is the only DVM tool I’ve had significant exposure too. So I can’t speak to the other COTS tools. I mentioned earlier in this blog a video on WhereScape and Snowflake. Although I haven’t used Erwin (in a data vault setting) and dbtvault, I mentioned them as they come up often.
Recently, a colleague of mine, also in the Boise area, hosted a Webcast on data vaults. At 30:43, there is a slide of a survey on using automation tools. The slide shows:
- 50% buy a tool.
- 30% build their own tool.
- 20% hand-code the Data Vault objects (ETL/ELT, schemas, etc.)
It’s a small sample, but OK for the purpose here.
Those figures suggest one of the gotchas. The data vault COTS automation tools are quite pricey – pricey enough so that 50% either go through the significant pain of building their own or hand-coding. The entire video is very good, providing insight into the current state of data vaults in the field.
Of course, it depends. Perhaps it’s because I’m a data guy I’m biased towards believing in “data as a strategic asset”, not just operational and tactical. Therefore, I believe that DDD and DVM represent core capabilities, which merits a well-designed, custom tool, even if it may be pricey.
Considering that the tools are rather pricey, much of the purpose for this blog is to demonstrate that the idea of DDD and DV is so critical that the value proposition of tools such as WhereScape is self-evident. The productivity gain of the developers alone should more than pay for the license.
Unfortunately, my experience with many customers is that cost of the DV automation tools have been prohibitive enough to kill the idea. To address that sore spot, I used much of my Covid-19 downtime building a CLI tool. I had planned on posting it on Github as an open-source project. But for several reasons, I ended up not having enough time preparing it for release (you know, that last 10% which is really 50%). It had a placeholder name of Top Ramen, because if you can’t afford real food, Top Ramen keeps you going. I’ll provide an update to that project in the future.
Mitigating Performance Issues
With Data Vaults we’ve traded off normalization for ease of extensibility. But there’s a catch in that more tables means there are more table joins. I don’t believe there is a universe where that doesn’t impede full performance potential. Additionally, the more complicated schema means more complicated SQL for the analysts to write.
This more complicated schema and performance impact are mitigated by what is called the “Business Vault”. The data vault of hubs, satellites, and links are raw data. The business vault is a database built from the raw data vault. The data would be cleansed, merged, transformed, and often formatted in a more familiar star/snowflake schema. In other words, the business vault is more of a familiar DW or data mart to which users generally interact – even though they can still access the raw data vault.
As was earlier discussed, a big difference between the traditional DW and DV is that the DW is of the old-school E-TL and DV is E-LT. With ETL, the transforms are done upfront before being loaded into the data warehouse. With ELT, we extract into the raw DV once and transform that raw data to multiple downstream use cases.
One of those downstream use cases is the good ol’ traditional star/snowflake, subject-oriented data marts, optimized for speedy slice-and-dice querying. Part of the data vault methodology includes the expectation that a cleansed, focused, star/snowflake data mart will be derived from the raw data vault.
Data Warehouse Acceleration – OLAP Pre-Aggregation
A pre-aggregation OLAP cube is as relevant to a data vault, as it is for our old friend, the traditional DW. Implementing an OLAP cube on top of a data vault at the most would require an unmaterialized view layer translating from the more normalized DV format to a star schema. Creation of these views are easily automated by interrogating the metadata of the data vault.
The best massively-scalable, full-featured, pre-aggregation, built for the Cloud OLAP engine is Kyvos Insights’ SmartOLAP. Full disclosure, I work for Kyvos Insights. However, my endorsement of that OLAP platform is my professional opinion based on over 20 years working with SQL Server Analysis Services (SSAS). I work at Kyvos because the Kyvos OLAP solution is the most worthy successor to the place SSAS once held in the BI world.
- Trillion Rows in Seconds at Global Banks – Ajay Anand, Pranay Jain. A nice and compact 15 minute video demonstrating the value of Kyvos’ OLAP solution.
- Data Vault Acceleration with Kyvos’ SmartOLAP – A blog I wrote for Kyvos introducing Data Vault to SSAS and Kyvos customers.
Additionally:
- The Kyvos objects (ex. Connections, Cube, processing) could be programmatically created and maintained from data vault metadata through Kyvos’ REST API.
- Kyvos plays very well into the ELT spirit. Kyvos includes built-in transformation features called Datasets. The great value is that because transforms are configured through a tool, the lineage of transformations configured in Kyvos is maintained.
Data Mesh and Domain-Driven Design
Before concluding, I need to briefly discuss the notion of a Data Mesh, which is picking up serious momentum in the data analytics space, at least at the time of this writing. Like Data Vault, it is an OLAP-side methodology and both clearly draws inspiration from Domain-Driven Design.
My claim in this blog is that the OLAP-side Data Vault is complementary to the OLTP-side Domain-Driven Design. However, Data Mesh is directly inspired by DDD – it’s much like an OLAP mirror image of an OLTP microservice. “Directly inspired” sounds like it trumps “complementary”.
But despite the DDD and OLAP roots, Data Vault and Data Mesh are indeed two very different things. Data Vault is a structure for the organization of a data swamp. Data Mesh is about decomposing a traditional, centralized, monolithic data OLAP infrastructure into loosely-coupled, domain-level “data products”. The brilliant insight by Zhamak Dehghani, the innovator who developed Data Mesh, is the notion of Data Products as the OLAP counterpart of OLTP microservices.
Figure 19 illustrates the juxtaposition of a couple of layers of enterprise-wide platforms components overlaid by columns of independent domains (Sales, Finance, Inventory). Each domain is responsible for the delivery and maintenance of its corner of the enterprise data in the form of data products meeting a set of Service Level Agreements and Objectives (SLA/SLO).
That is, as opposed to each domain throwing their analytics development burdens over the fence to a centralized team of data engineers who maintain a centralized, monolithic data warehouse, who in turn it toss it over another fence to the many consumer analysts throughout the enterprise. All the while, the centralized DW team doesn’t have deep domain knowledge nor a deep understanding of how the data will be used by the analysts.

The hexagons (with arrows pointing in and out) towards the top-middle of Figure 19, within the yellow box, represent Data Products owned by the domains and exposed outside of the domain to enterprise consumers. These data products offer consumers across the enterprise a catalog of highly-curated data from which to flexibly compose whatever view of data they require. The blue “wiring” connecting the data products represents loosely-coupled relationships between the data products. That, I believe is the “mesh” in data mesh.
Notice though, that a Data Vault Layer (deployed on, say, Snowflake or a Databricks Lakehouse) can serve as a common, flexibly-structured, scalable, reasonably-performant platform onto which all domains can plug in their raw data which will ultimately surface as data products. The satellites are color-coordinated to the domain.
A benefit of the Data Vault as a common architecture across domains stems from the add-only quality of a Data Vault – no updates to existing rows or deletions. It means it’s immutable. The immutability of a Data Vault promotes more consistency within the Data Products. That improved consistency within the Data Products promotes reliable composability of the Data Products into composite Data Products.
It’s an important consideration because the self-service nature the Data Products can easily result in what could be described as Data Smog. Business Rules will start embedding in an unmanaged slurry of self-service reports, Jupyter notebooks, and SQL. Be sure to manage this with a data catalog or metadata management system.
At the time of this writing, Data Mesh dictate an enterprise-wide platform as far as what happens upstream of the Data Products. Meaning each domain is free to use whatever tools and methods they wish to create the data products. At minimum, the data product can be registered into a enterprise-scoped data catalog, is in a readily consumable format, and meets agreed-upon SLAs. I think for all intents and purposes, “readily consumable” can mean it’s easily connected to tools such as PowerBI and Tableau, and of course, through Jupyter notebooks.
However, if an organization could settle upon a common enterprise analytics platform (such as Snowflake, Databricks, or Azure Synapse), reducing the set of required skills eases the burden on already hard-to-find data engineers. There would be more possibilities for the data engineers to be fluidly shared among a few hopefully similar or adjacent domains.
Conclusion
As I said at the beginning, DDD and DVM are two sides of the same coin. That’s the message of this blog. But my motivation for writing this blog is the belief I still hold that the smartest should win – or at least smartness reduces the portion of success dependent on luck. We can’t be smart by running away from or ignoring complexity. DDD and DVM aren’t magical bullets, but they are the strategy for embracing complexity.
The weird year of 2020 brought front and center not just the value of analytics but the lacking ability to interpret it. No matter which sides of the many critical issues currently in play that you’re on, I think we can agree that even the best experts are still really bad at interpreting data. They are humans and they are prone to biases and errors. Therefore, we all need to upgrade our enterprise’s ability to interpret data for ourselves.
The complexity of the world and the speed of change will only continue to grow. Short of a true A.I. that’s vastly superior to our collective human intelligence, the approach I present in this blog seems to be the most realistic way to raise and maintain the IQ of the entity we call the enterprise. That is, bridging the physical world, human intelligence, and machine intelligence.
This blog is Chapter IX.1 of my virtual book, The Assemblage of Artificial Intelligence.
Glossary
Business Vault – A set of database tables derived from data within a Data Vault. The business vault schema intended to better serve the needs of a target audience in terms of relevant data and query performance. It would usually be a star/snowflake schema derived from the Raw Data Vault.
Code as Documentation – Treat executable artifacts (code, tests, schemas) as the authoritative spec. Docs are generated from, or point back to, the code so behavior and intent can’t drift.
Commercial Off-The-Shelf (COTS) – Ready-made solutions that can be purchased from vendors.
Domain-Driven Design (DDD) – A methodology for approaching software design introduced by Eric Evans.
Domain Model – A structured map of the business: core entities, value objects, events, and rules expressed in the ubiquitous language. It guides OLTP design (DDD) and feeds analytics design,
Data Vault (DV) – A data warehouse constructed using the Data Vault Methodology.
Data Vault Methodology (DVM) – A methodology introduced by Dan Linstedt for the construction of a data warehouse that is amenable to rapidly adding data sources and modifications.
Extract-Load-Transform (ELT) – Copy data from sources, load it raw into the platform (e.g., Snowflake), then transform inside the platform. Optimizes for agility and scalable compute.
Extract-Transform-Load (ETL) – Copy data from sources, transform in-flight (staging/ETL tool), then load the shaped result into the warehouse. Optimizes for curated, pre-modeled targets.
Event Sourcing – The notion of recording every elemental change to a database. For example, if a customer’s street address and/or phone number changes, each is recorded as separate events.
Event Storming – A methodology for the discovery and organization of processes.
Functional Programming (FP) – A paradigm emphasizing pure functions, immutability, and composition. Useful for data/analytics pipelines because it yields predictable, testable transformations and rule logic.
OnLine Analytical Processing (OLAP) – To old-school SSAS people like me, OLAP refers to the technology that pre-aggregates and manages data in a star/snowflake schema. However, OLAP today seems to refer to the act of the query pattern that reads a lot of data, does some crunching (like aggregating sums and counts), and returning some result.
OnLine Transactional Processing (OLTP) – Query patterns that deal with many users creating, reading, updating, and deleting a small amount of data at one time.
Raw Data Vault – The part of a Data Vault that holds unadulterated data, extracted and loaded into the data vault with no transformations.
TDW – Traditional Data Warehouse. A data warehouse built from one of more star/snowflake schemas.
Unified Modeling Language (UML) – A specification for documents that capture software requirements.
© 2019-2021 by Eugene Asahara. All rights reserved.
