Essays for the NoLLM Epoch (Not Only LLMs)
By: Eugene Asahara
First Published: September 14, 2025
Abstract
Intelligence is not a monolithic super-structure, but a living assemblage—a dynamic system of interconnected parts that together create something far greater than any one component. Real intelligence emerges in environments where events unfold through time, processes interact, and decisions shape future outcomes. In such systems, intelligence is not merely recognition or prediction; it is the ability to observe processes, learn from them, and deliberately influence how they evolve.
A successful business provides a powerful model of this kind of intelligence. Businesses integrate streams of events—sales, operations, supply chains, and customer interactions—into a coherent system that learns, adapts, competes, and survives in a complex world. Data becomes memory. Processes become stories about how things work. Decisions become plans that reshape those processes. Through this continual cycle of observation, interpretation, and action, organizations develop a form of collective intelligence that operates across time.
The Assemblage of Artificial Intelligence applies this same model to AI. In this NoLLM epoch—Not Only Large Language Models—we move beyond the idea that intelligence resides inside a single model. Instead, enterprise intelligence emerges from assembling proven components into a coherent system. Knowledge graphs provide structured memory and relationships. Prolog-style logic enables transparent reasoning and causation. Business intelligence systems capture and analyze processes unfolding through time. Machine learning discovers statistical patterns in those processes. Large language models act as the connective and creative layer that helps interpret and communicate them.
Together these systems transform raw events into reusable artifacts of intelligence—stories, procedures, strategies, and plans that guide future action. Just as a business organism thrives through symbiosis and synergy, this hybrid architecture allows intelligence to emerge from collaboration between systems rather than from a single black-box model. The result is auditable, scalable, human-grounded AI that preserves agency while amplifying collective capability.
Drawing on more than 25 years of building enterprise systems, this work offers a practical blueprint for the next phase of AI: not replacing human originality, but strengthening the systems through which organizations observe reality, understand processes, and shape the future.
Preface – “Book” Three of the Enterprise Intelligence Trilogy
Over the past fifteen years, especially lately (2022–2025), I’ve written a number of long-form essays (blogs) on AI subjects—typically 15 to 45 minutes to read. These essays circle around my favorite activity of thinking about thinking. They are grounded on my experiences as a business intelligence (BI) developer/architect for over 25 years, but also unshackled by the freedom of thought I grant for myself.
In addition to these essays, I have written two traditional printed books over the past two years. They are about building AI on top of a solid BI foundation: Enterprise Intelligence (June 21, 2024) and the more recent Time Molecules (June 4, 2025), published by Technics Publications (Thank you to Steve Hoberman for publishing the first two volumes.)
This page is the scaffolding for the third and final book of the “Enterprise Intelligence” trilogy. It isn’t a chronological archive; it’s a curated sequence of the essays, grouped into broad topics (parts) and arranged like a conventional book to tell a coherent story of “an assemblage of artificial intelligence.” It includes only the pieces that serve this narrative, not every blog I’ve written. As this AI era is rapidly evolving and I’m still very much thinking about thinking, it is a work in progress.
Intelligence is a System of Components
We are in the NoLLM (Not Only LLMs) epoch (sub-era) of the LLM Era of AI. Just as the NoSQL movement expanded beyond relational databases without discarding them, this era expands beyond LLMs by recognizing LLMs as just one component of intelligence. Those components include AI Blasts from the Past—expert systems (1980s), knowledge graphs (2000s), non neural network machine learning algorithms (2010s)—as well as knowledge models, reasoning engines, and performance frameworks.
Note: Earlier, when NoSQL was a popular meme, people took it to mean something along the lines of “anything but SQL”. The meme was “NoSQL” with a slanted red line through it—like no smoking signs. The “o” was lower-case so that’s what it looked like: No. However, the more popular interpretation became “Not Only SQL [databases]”. That’s the analogous interpretation I use for NoLLM—Not Only LLMs, but including other components of AI.
This third volume is different: a living book for the NoLLM Epoch of the LLM Era of AI. Spanning the years 2023–2025, it extends the arc of my two printed works into an ongoing collection, continually refreshed as new essays are added and older ones updated.
The history of AI resembles the evolution of the brain. The neocortex may be the newest layer, but the older structures—the limbic system and brainstem—still carry vital roles. In the same way, LLMs are our neocortex: powerful and recent, yet built atop foundations that remain indispensable. I see LLMs as the piece that takes on the complexity of the world, whereas the others are more mechanistic, which is great for a simple or complicated processes. Expert systems, knowledge graphs, and non-neural machine learning didn’t vanish when LLMs arrived. Together, old and new form the full architecture of intelligence.
Figure 1 illustrates the assemblage of AI components as both a lineage and a living system.
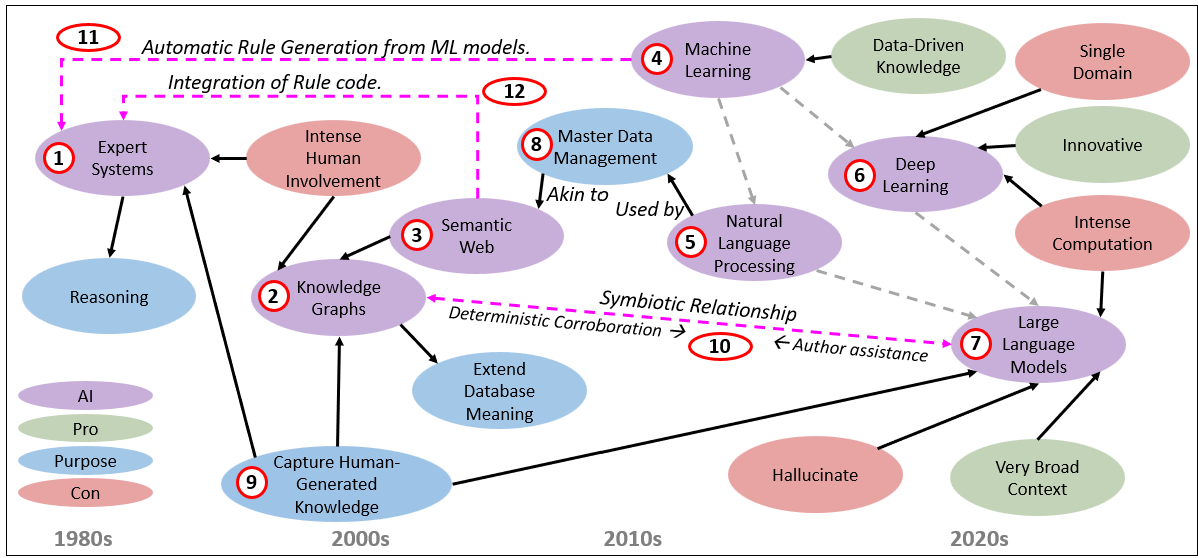
Here are the descriptions of each numbered item in Figure 1. The numbers do jump around, but at least the first seven (the purple AI nodes) are left to right (1980s through 2020s). The dates represent when the item became mature enough and had significant traction:
- Expert Systems (1980s) Hand-authored rules captured slices of expert knowledge in domains like medicine or troubleshooting. Their limitation was brittleness—rules could only cover what humans explicitly wrote.
- Knowledge Graphs (2000s) Born out of the Semantic Web vision, knowledge graphs structured entities and relationships at scale. They made meaning machine-readable, curating knowledge with ontologies and metadata. Unlike expert systems, they could interlink across domains.
- Semantic Web (2000s) An attempt to formalize the standards that made knowledge graphs interoperable—RDF, OWL, SPARQL. The dream was universal integration, though the execution was more fragmented.
- Machine Learning (2010s) Classic ML—decision trees, SVMs, clustering, assocations—moved beyond hand-authored rules by training on data. Human experts still selected features and tuned hyperparameters, but machines could find statistical regularities more flexibly than rules alone. Over the past few years, those design and implementation tasks are being automated with MLOps tools such as Azure Machine Learning with MLFlow.
- Natural Language Processing (2010s) Earlier NLP relied on heuristics—word counts, stop words, n-grams, parsing trees. It was valuable but fragile and not very robust, requiring careful human curation and lots of exceptions.
- Deep Learning (2006 foundations, 2012–present) The deep learning era began with Hinton’s work on deep belief networks (2006) and exploded with the ImageNet moment (2012, AlexNet). With GPUs, large labeled datasets, and scalable neural nets, deep learning came to dominate computer vision, speech recognition, and later NLP. Despite breakthroughs, these models were domain-specific and data-hungry, excelling in pattern recognition but still narrow in scope.
- Large Language Models (LLMs, 2022–present) Transformers scaled to unprecedented size created the AI summer of all AI summers. LLMs can generate fluent language and capture broad context, though at the cost of opacity, hallucinations, and immense compute needs.
- Master Data Management (2010s) For enterprises, MDM was the practical effort to disambiguate and standardize. The arrow to Semantic Web (3) is just saying that the Semantic Web is to Knowledge Graphs items as MDM is to database objects.
- Capture of Human-Generated Knowledge (cross-era theme) Not a single era, but a current running through AI’s history.
- In Expert Systems (#1), humans encoded rules directly.
- In Knowledge Graphs (#2), humans curated concepts and ontologies.
- In LLMs (#8), human text at massive scale became the training substrate.
This through-line shows that every AI era has relied, in different ways, on harvesting and structuring human knowledge.
- Symbiosis of LLMs and Knowledge Graphs (present) Today the pendulum swings toward integration: LLMs help author and maintain knowledge graphs, while knowledge graphs verify and ground LLM outputs. The probabilistic and the structured, working side by side.
- Automatic Rule Generation with ML Machine learning can now generate candidate rules—essentially drafting the kind of logic that once had to be hand-authored in expert systems. What began as statistical pattern-finding (#6) feeds back into symbolic reasoning (#1).
- Globally Recognized Names Semantic Web naming can be used to name rule symbols. For example, symbols used by Prolog could use RDF/OWL identifiers (IRI).
Of course, Figure 1 is an extremely simplified view of the AI history, and from my BI-biased perspective.
Organized Set of Essays
Originally, I had planned to complete a trilogy with this third book as a traditional printed book through the same publisher. That project didn’t move forward, and that turned out to present an interesting alternative path. The traditional book format, for all its strengths, carries restrictions that don’t work well for a field moving as quickly as AI. By organizing this third volume as a curated collection of essays, I gain advantages that a bound book can’t offer:
- I can release new sections in a continuous update (new essays that I’ll add to this “book”, where warranted, instead of waiting years for a new edition. It’s kind of like waiting months or years for software “service packs” before CI/CD. This is especially critical for a topic that is evolving at a ridiculous rate.
- I have more freedom with the images, especially in regard to information density and color-coding, which doesn’t translate as well on paper.
- I can link directly to Web pages. That includes GitHub code repositories, which is handy for a software book. In fact, there is a supplemental Github repository for Enterprise Intelligence and Time Molecules.
- There is the Search function on the right-bar of this blog site to serve as a robust Index with access to the entire site.
As an organized set of essays, most of them have been written to stand on their own. I realize that people aren’t reading books nearly as much, instead opting for 10-30 minute YouTube videos, where the dynamic presentation can be much more visually appealing and rich. So it’s like one of those books, where you can skip around and gain something of value from just one or a few of the essays.
Additionally, in order to express everything I want to say about AI and data—just what’s on my mind right now—would take a book of well over a thousand more pages. No one wants to read that and I don’t want to write that. However, writing these essays is the most important part of my daily routine—how I spend my “Deep Work” (Cal Newport) time. So this method of releasing pieces with this agile methodology is a better way to address the incredibly fast evolution of AI, and consequently the way the world works.
This is not a traditional, “there in black and white”, bound book. It’s more like a YouTube channel “Playlist”, an organized collection of [mostly] stand-alone essays that describe aspects of intelligence beyond the dominant large language models of this AI era.
The disadvantage is that the self-contained essays contain some redundancies that aren’t streamlined out—for example, background needed to mitigate the need for pre-requisite reads. Some essays may not fit in just the single group I chose for it here, spilling over into other groups. But that’s the price for the ability to read them independently in any order (even though I’ve organized the essays into a logical order).
Reading either or both of the printed books isn’t a pre-requisite either. Similarly, I did write Time Molecules to stand alone from Enterprise Intelligence, even though it is also a logical sequel. However, both of those books encapsulate what I’ve learned over 25+ years attempting to add more of an AI aspect to business intelligence (BI).
To be clear, this organized collection of essays isn’t intended to rehash what I already cover in the two printed books. It’s intended to extend beyond those first two books.
How to Use this Book
Following is a Table of Contents. It contains only titles, with each blue title linking (all the blue text are links) directly to its respective blog post on this site. The ToC is meant as a succinct list so all the chapters can be seen together at a glance. Figure 2 illustrates how to navigate the ToC, summary, and the actual blog:
- Scroll down to the Table of Contents.
- Click on the blog title to navigate to the blog. It will open to the blog on eugeneasahara.com
- Alternatively, click on Summary and you will be taken to a short summary of the blog on this page.
- If the summary indicates something you’d like to read, you can click on the blog title to navigate to the blog on eugeneasahara.com
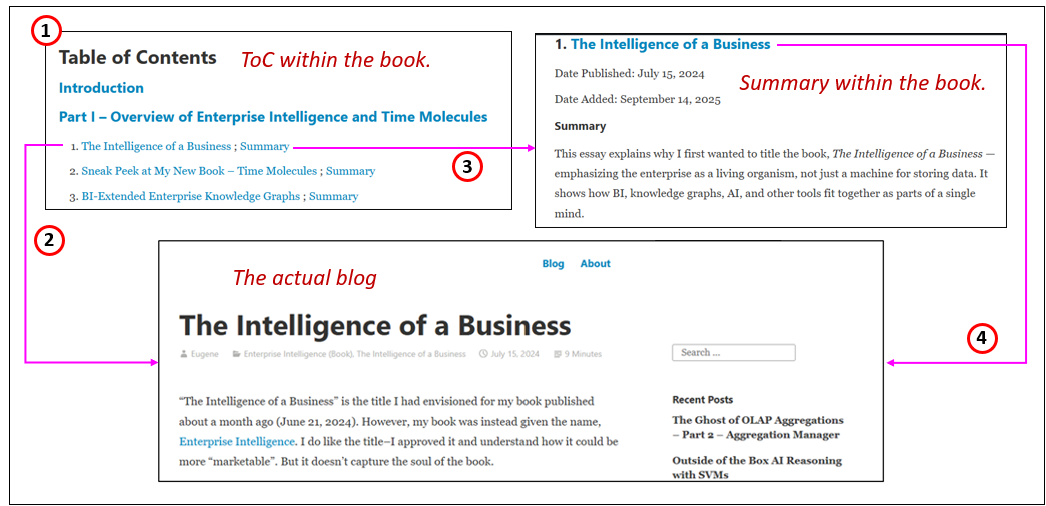
Navigation hints:
- After clicking on a Summary link in the ToC, click the browser back arrow to return to the ToC.
- For most of the Parts, the first essay of each Part is the most important. It’s usually the introduction to the topic—you’ll get the gist of what the Part is about. That goes for Parts I, II, III, V, VII, VIII.
So yes, there are two links to each essay: one in the ToC and one in its summary.
Lastly, please note that this book was published on September 14, 2025. Much of the text (intros and summaries) in this document are written in the context of that timeframe.
Table of Contents
Introduction
Part I – Overview of Enterprise Intelligence and Time Molecules
- The Intelligence of a Business ; Summary
- Sneak Peek at My New Book – Time Molecules ; Summary
- BI-Extended Enterprise Knowledge Graphs ; Summary
- AI Winter, Good Timing for My Book ; Summary
- Charting The Insight Space of Enterprise Data ; Summary
- Key Takeaways from My Two Upcoming DMZ 2025 Sessions ; Summary
- The BI Counterpart to Infinite Context ; Summary
Part II – The Foundations of Intelligence
- Analytics Maturity Levels and Enterprise Intelligence ; Summary
- Exploring the Higher Levels of Bloom’s Taxonomy ; Summary
- Correlation is a Hint Towards Causation ; Summary
Part III – Artificial Goals and Feelings
- Bridging Predictive Analytics and Performance Management ; Summary
- Levels of Pain: Refining the Bad Side of KPIs ; Summary
- The Effect Correlation Score for KPIs ; Summary
- KPI Status Relationship Graph Revisited with LLMs ; Summary
- KPI Cause and Effect Visio Graph ; Summary
Part IV – The Data Processing of Sentience
- From Data Through Wisdom: The Case for Process-Aware Intelligence ; Summary
- Thousands of Senses ; Summary
- Analogy and Curiosity-Driven Original Thinking ; Summary
Part V – Graph Structures Beyond Ontologies
Part VI – Machine Learning in the LLM Era
- Thinking Outside of the Box is About Sacrifice ; Summary
- Embedding Machine Learning Models into Knowledge Graphs ; Summary
- Reptile Intelligence: An AI Summer for CEP ; Summary
- Stories: The Unit of Human-Level Intelligence ; Summary
- Context Engineering ; Summary
Part VII – Prolog in the LLM Era
- Does Prolog Have a Place in the LLM Era? ; Summary
- Prolog AI Agents ; Summary
- Playing with Prolog ; Summary
- Prolog and ML Models ; Summary
- Prolog and Business Intelligence ; Summary
- Four Levels of Intelligence ; Summary
- Knowledge Graphs vs Prolog ; Summary
- Deductive Time Travel ; Summary
- Prolog Strategy Map ; Summary
- Closer to Causation ; Summary
- Thinking Deterministically or Creatively ; Summary
- Trade-Off / Semantic Network – Prolog in the LLM Era – AI 3rd Anniversary Special ; Summary
Part VIII – Pre-Aggregated OLAP
- The Role of OLAP Cubes in Enterprise Intelligence ; Summary
- The Ghost of MDX ; Summary
- An MDX Primer ; Summary
- The Ghost of OLAP Aggregations – Part 1 – Pre-Aggregations ; Summary
- The Ghost of OLAP Aggregations – Part 2 – Aggregation Manager ; Summary
Part IX – Horizontally Scalable Architecture
- Data Vault Methodology paired with Domain Driven Design ; Summary
- Embedding a Data Vault in a Data Mesh ; Summary
- Embedding a Data Vault in a Data Mesh – Part 2 of 5 – Event Storming to Domain Model ; Summary
- Map Rock – 10th Anniversary and Some Data Mesh Talk ; Summary
Part X – Planning
Part XI – System ⅈ
- System ⅈ: The Default Mode Network of AGI ; Summary
- Explorer Subgraph ; Summary
- Chains of Unstable Correlations ; Summary
- The Insight Function Array ; Summary
Part XII – The Third Act
- The Products of System 2 ; Summary
- Time Molecules, AI Agents, and Context Engineering ; Summary
- Building System 1: How Markov Models and ML models are created and added to System 1.
- The Process of System 1:
- The System ⅈ Processes of the Insight Space Graph: The insights from the ISG, built in a System ⅈ process, that surfaces as “thoughts” to System 1 and System 2.
- The Process of System 2: A deep dive into the iterative and recursive process of converting written text into a Prolog plan—beyond a one-shot call to an LLM.
Introduction
Over the decades that computers have existed, there have been a few AI summers with long periods of AI winters. Each was rather unique, taking a stab at elusive AI from different angles. Some were version 2.0’s of prior efforts—for example, LLMs (the current AI Era) as a much better version of NLP. These are the major AI Eras that spanned by career period that began in 1979, with descriptions of the “Summer” and “Winter”:
- Expert Systems Summer (1980s) Symbolic reasoning surged with Prolog, Lisp, and rule-based shells. The hype was enormous—Japan’s Fifth Generation Computer Project promised reasoning machines that would rival supercomputers. Corporations invested heavily in expert systems for diagnosis, configuration, and business rules.
- First AI Winter (late 1980s–early 1990s) Expert systems hit scaling walls: rules were brittle, expensive to maintain, and couldn’t handle ambiguity. Hardware investments in Lisp machines collapsed. Funding dried up, research slowed, and “AI” became a dirty word in many industries.
- Semantic Web & Knowledge Graphs Summer (late 1990s–early 2000s)
The dream shifted toward a machine-readable web. Standards like RDF, OWL, and SPARQL promised universal interoperability. Enterprises experimented with ontologies and metadata catalogs, while academics pushed Tim Berners-Lee’s “Semantic Web.”- Second AI Winter (mid–2000s)
The Semantic Web overpromised and underdelivered. Ontology engineering proved costly, adoption lagged, and the broader tech world moved toward simpler Web 2.0 and search-based approaches. The field cooled, surviving mostly in enterprise knowledge graphs.
- Second AI Winter (mid–2000s)
- Machine Learning & Data Science Summer (2010s) Statistical learning and the explosion of data put AI back on the map. Random forests, gradient boosting, and ML pipelines became standard practice. “Data Scientist” was crowned the “sexiest job of the 21st century”, and every enterprise raced to hire talent.
- Deep Learning Summer (2012–2020s)
Instead of a winter, ML was swallowed by something bigger. GPUs and massive datasets unlocked deep learning. CNNs conquered vision, RNNs and LSTMs pushed speech, and transformers opened the door to language. The ImageNet moment in 2012 marked the start of this era, and the pace accelerated without a pause. - Large Language Models Summer (2022–present)
I see LLMs as “NLP 2.0”, beyond “on steroids”—more like the gamma rays that made the Incredible Hulk. Transformers scaled into general-purpose reasoning engines—ChatGPT, LLaMA, Claude, Gemini. The hype is global, with both excitement and fear of overreach.- Impending Winter? (TBD) Signs of fatigue are already visible: hallucinations, high costs, diminishing returns from simply scaling models larger. If expectations overshoot reality, another winter may follow. What survives will be the enduring components—knowledge graphs, logic, and process models—woven together with LLMs into more balanced systems.
Even though the AI eras have not yet yielded a Rosie (Jetsons), C3PO, or Commander Data, the core technologies of a previous era were not superseded with the technology of the next era. Rather, the solutions were attempts from different directions.
Intelligence shouldn’t be looked at from the point of view of a thing—some sort of organ, in this AI Era, an LLM. Intelligence is a system, an assemblage of capabilities and processes woven into a classic example of the whole being greater than the sum of its parts. Our human intelligence evolved over hundreds of millions of years, under a fortunate sequence of contexts, that lead to our human intelligence.
But evolution created the platform and some bootstrap programs (kind of like a BIOS). The rest of the intelligence trained into us through observation of what we’re exposed to—things going on around us (culture, environment), what we’re taught about skills those before us thought are important to convey (our formal education). It’s also training from the procedures we’ve learned in attempts to relieve whatever suffering we encounter—that can include the fear of having a tough life without graduating from high school, the desire for recognition.
The Assemblage of Artificial Intelligence
Figure 3 is a simplified illustration of how the parts from AI Eras past and a couple of pieces of AI Eras of the future fit together. The diagram uses shaded regions to group related components into functional clusters. Figure 1 and Figure 3 differ in that the former is about the characteristics of the AI Eras and the latter shows how the stars of each era fit together into a system.
The gray box in the upper right highlights Deep Learning as its own domain, subdivided into applied and strategic categories. This shading emphasizes that deep nets—though a single family of methods—split into two distinct modes: scalably created and maintained applied models for vision and categorization, and resource-intensive strategic systems like AlphaFold or AlphaZero.
The other shaded area, the arc of Ontologies & Taxonomies (3), Semantic Layer (8), and the Graphs beyond Ontologies & Taxonomies (11), merge to form an Enterprise Knowledge Graph—the end-product of Enterprise Intelligence.
The legend reinforces structure by color-coding categories of AI components:
- Blue (ANN) — Neural networks and LLMs, the probabilistic models of the current era.
- Yellow (Human) — Knowledge structures authored by people: expert systems, ontologies, and taxonomies.
- Green (Data) — Foundations drawn from BI: integrated sources, event streams, and semantic layers.
- Purple (ML) — Classic machine learning models that are transparent and still widely used.
- Red (Process) — Orchestration layers like MLflow and reasoning frameworks, which organize how all the other components operate together.
This palette of colors and shading helps you to see at a glance which parts of the assemblage were hand-crafted by humans, which are data-driven, which are probabilistic neural methods, and which are coordination mechanisms. It visually encodes the central theme: AI is not one technology but a layered assemblage, where each color marks a different lineage that still contributes to the whole.

Descriptions of the numbered components of Figure 3:
- Large Language Models (LLMs) The hallmark of the current era, LLMs excel at integrating and translating text. They act as a conversational interface, connecting humans with data and processes. Like the neocortex in the brain, they are powerful and recent, but not sufficient on their own.
- Rules & Symbolic Expert Systems Prolog, Lisp, and SWRL exemplify this tradition. They capture explicit logic and structured reasoning. Though overshadowed by newer methods, they remain indispensable for precise, auditable rules.
- Ontologies & Taxonomies Knowledge graphs and the semantic web formalize relationships between concepts. They extend meaning beyond raw data, much like shared vocabularies that make communication possible across systems.
- Classic Machine Learning (Non-Neural) Before deep learning, data scientists focused on interpretable models like decision trees, association rules, clusters, and regressions. These remain transparent and valuable, offering insights where interpretability and governance matter.
- Deep Learning The workhorse of the 2010s and beyond, deep learning comes in two forms: applied models like computer vision and categorization, which scale across applications, and strategic systems like AlphaFold or AlphaZero, which demand enormous compute but deliver specialized breakthroughs.
- Data Integration (BI Foundations) Data mesh, data vault, and other integration frameworks unify sources into coherent structures. These efforts accelerate the onboarding of new domains and provide the substrate for analysis.
- Event Data IoT streams, ML predictions, and system instructions are all events. Abstracted into case, date, and event, they provide the time-stamped pulse of enterprise activity. Time Molecules extend this view by focusing on the temporal patterns themselves.
- Semantic Layer (Data Catalog) The semantic layer integrates data from sources (6) and events (7) into a navigable catalog. In BI, this functions like OLAP cubes—an organizing framework for consistent meaning across queries and domains.
- MLflow (Orchestration of Machine Learning) A platform for design and deployment of ML models, MLflow scales experimentation, tracking, and rollout. It relieves data scientists from repetitive tasks, allowing faster iteration and broader adoption of AI pipelines.
- Reasoning Orchestration Mechanisms such as chain of thought, retrieval-augmented generation, and mixture of experts break problems into steps, iterate on alternatives, and test results. It’s the most connected piece. This is where LLMs, rules, and data models combine into workflows.
- The relationship from reasoning orchestration (10) to Event Data (7) highlights another major source of a wide scope of events not only from IoT. Orchestration is about coordinating processes—processes that may not follow the same sequence for each iteration. This opens the door for deep process mining and systems thinking as I describe in Time Molecules.
- Graphs beyond Ontologies & Taxonomies The end product of the Enterprise Intelligence framework, the EKG integrates ontologies (3), semantic layers (8), and broader enterprise data into a unified graph. It represents the memory and context of the enterprise, connecting disparate elements into one reasoning fabric.
Avoiding Premature Convergence
Is the summit of the “LLM path to AGI” only “smart enough to be dangerous”? LLMs of today are attractive because many people can use them effectively, so we are vulnerable to the premature convergence of the LLMs on this current AGI path.
In fairness to the state of AI today, we have moved beyond LLMs—the current AI golden child, as the definition of AI. Frameworks such as Retrieval Augmented Generation (RAG) and Chain of Thought implement LLM utilization as an iterative and nested process. But as of 09/14/2025, the general public (including those in high tech but not directly working on AI) only hear about the antics of the major LLM products/players such as ChatGPT (OpenAI), Anthropic, DeepSeek, Gemini (Google), Llama (Facebook), etc.
It may actually be fortunate that earlier AI summers collapsed into winters. Expert systems and the Semantic Web were nowhere near “almost there”—they simply weren’t good enough for much. The hardware and the rest of the world were not ready. They were still dealing with computers in general (expert system days of the 1980s) and dealing with the Internet (semantic web days of the 2000s).
LLMs are different. Despite hallucinations and their frustrating inability to think beyond their own boundaries, they are good enough at many tasks to scale. And that is the real danger: when a technology is merely good enough, it tends to dominate, locking us into early versions and narrowing our imagination. Evolution calls this premature convergence—not fatal but limiting. Once scaled out and massively deployed, retrofitting becomes logistically messy.
The alternative is to treat intelligence not as a single organ, but as an assemblage: logic, graphs, processes, and language woven together. If we can resist the temptation to stop at “good enough”, we may still have the chance to build something greater than the sum of its parts.
Machine Learning AI of the 2010s
I don’t include the components of the ML AI Era, mostly in the form I’m accustomed to through Azure AI Services (formally Azure Cognitive Services)—the very technologies that are the focus of my Azure AI Engineer certification. These are still very much part of an AI system, but they occupy a different tier—less glamorous and robust than LLMs, yet essential capabilities for any working assemblage of intelligence.
- Computer Vision — interpreting the visual world, identifying objects, detecting anomalies, and reading images as data.
- Speech to Text — turning spoken words into written form, enabling transcription, call analysis, and voice-driven input.
- Text to Speech — rendering language back into humanlike voices, making interaction more natural.
- Language Understanding — extracting intent and meaning from text, powering chatbots and conversational agents.
- Anomaly Detection — watching data streams for subtle deviations, surfacing potential problems before they cascade.
- Translation — bridging human languages in real time, extending communication across boundaries.
- Automated ML (AzureML) — Platforms can now automate feature selection and hyperparameter tuning, removing much of the routine 80% of data science once thought to define the role.
These services may lack the aura of “artificial general intelligence”, but they form the sensory and interpretive capability of modern AI. They convert the raw material of perception—sights, sounds, languages, signals—into the structured inputs upon which reasoning, prediction, and strategy can build. But they hardly ever had any press with the general audience. Without them, the higher-order reasoning of knowledge graphs, process models, or LLMs would have little to work with.
The last point about Automated ML (AzureML) deserves a little more mention. This was one of the first shocks that the profession of data science wasn’t untouchable. The once “sexiest job of the century” was suddenly stripped of much of its mystique, as automation quietly absorbed tasks that once required years of practice. What remained valuable was not parameter-tweaking, but the harder work of asking the right questions, interpreting ambiguous results, and aligning models with strategy. Even at that, LLMs are intruding on those tasks.
Note on My Intent
The purpose of this book is to organize the essays I’ve posted on this site over the years. These essays are meant to share my experience and thoughts towards the purpose of providing insights for my software developer colleagues. In fact, that’s the purpose for the trilogy of books. It’s not to promote AI as a product or to champion unchecked adoption and unbridled hurtling towards AGI and ASI. AI, like every transformative technology, can be used for purposes of concentration, control, and exploitation by corporations and governments—yes, it has happened a few times in human history.
There’s not much I can do about where AI heads and what others do with it. But I can help to widen the awareness of what AI encompasses, what components it is built from, and how the parts fit together. I hope to broaden peoples’ minds on AI the same way an understanding of psychology is very personally useful. The more people understand the bigger picture and the inner workings, the less they are at the mercy of hype, marketing, or fear. Knowledge of AI is not an invitation to surrender agency, rather I intend it is a means to maintain it.
I’m a software developer, one of those who loves really tough problems and gets my kicks trying to figure them out. I’m not an evolutionary biologist, an evolutionary psychologist, a neuroscientist, or any scientific expert. I know data structures and software and how to solve bleeding-edge business problems with them. But for at least three decades, I’ve studied and taken tremendous inspiration from those fields in order to look beyond the focus of the time. My apologies upfront for the liberties I’ve taken swimming out of my lane with these wonderful fields in order to convey concepts to a BI audience. Whatever I apply outside my swim lane are merely for analogy and inspiration. Remember, the really neat stuff is in the qualities of the relationships between domains. Right?
Full disclosure, my only horse in the race is Kyvos Insight’s OLAP and Semantic Layer product. I’m currently a Principal Solutions Architect at Kyvos. The characteristics of OLAP and the Semantic Layer are not “AI” per se. Kyvos and the BI world is about building a trustworthy data infrastructure for consumption by human and machine intelligence. That’s something that doesn’t go away because of AI. I describe the value of OLAP in Part VIII.
A Little Note on LLMs and My Writing
As of 2025-2026, LLMs are incapable of helping me with the non-traditional thinking I like to write about. I’ve tried, and it always loses my point, insisting on shoving the square peg I’m writing about into the round hole that it already knows.
I occasionally include AI-generated excerpts in my blogs—almost always edited by me to some extent, the exception being when I’m demoing its result verbatim. When the work is AI-generated, it’s explicitly stated. The bulk of my material is written by me, from scratch. That’s especially important when exploring subjects at the cutting or bleeding edge—areas where AI still can’t quite articulate what I’m after. I use AI as an assistant, not as a collaborator. In fact, one of the central ideas of my work is that this—human direction paired with machine assistance—is how AI delivers its greatest value. I honestly wish it could be more effective at generating original content on the cutting or bleeding edge, but for now, it’s incapable of that.
And yes, I use a lot of m-dashes. There are a few things about the way ChatGPT “talks” that I like and have adopted—m-dashes is one of them.
TC;FI — Too Complicated ; Forget It
All that I’ve written about in my two books and the blogs that comprise this virtual book might seem overly complicated. That’s probably especially true now after years of TikTok and AI conveniently handling more and more of our need to think.
AI really is like highly-processed food. Like our highly-processed, readily obtainable, and relatively inexpensive food, AI is convenient and pretty good (sometimes surprisingly good). That food avails way more calories than we could ever burn unless we’re manually working farmland. The other similarity is that as that food comes with weight problems, I easily notice when I rely too much on AI, my brain starts to get flabby. Of course, AI saves me from countless hours researching and debugging. That makes me that much more productive. But I always wonder what will happen to my productivity if it’s taken away.
What I’m really trying to say is that I want to promote the ability to think by offering the insights into analytically systems built from over 40 years of intense experience building them. I’ve surfed several AI waves, each time thoroughly enough to have crashed into the walls of the time. Which meant that when subsequent technologies came along, I could readily recognize their value because I hoped and prayed for them years ago.
I’m never satisfied with how much I’ve tried to generalize the components I’ve written about into the fewest concepts possible. We’ve always been trying to unify phenomenon into some grand unified theory. Sometimes we figure out something (like the Earth revolves around the Sun or all species collapses to a tree of gene evolution) and many parts coalesce into fewer parts.
It might be that there are just a few elegant aspects to intelligence, not a few dozen or hundreds. But I remind myself that the “brain” is really many integrated components, and even includes parts not traditionally considered part of the brain.
Part I – Overview of Enterprise Intelligence and Time Molecules
This book is intended to stand on its own, but an overview of my prior two books, Enterprise Intelligence and Time Molecules, helps set the stage. The first revealed the enterprise as an organism, its enterprise knowledge graph (EKG), the nervous system that gave shape to information and structure to decision-making. The second shifted from structure to motion, showing how time itself could be treated as a substance, broken into molecules of process that revealed the rhythms of work and the probabilities of what comes next.
What follows in this opening section traces those foundations. Each essay revisits a key idea from the earlier books, but not as repetition. They serve instead as orientation—reminding the reader of how structure and time were established, and why those dimensions had to be unified. Only then can the assemblage be seen for what it is: the convergence of reasoning, goals, and systems of thought into something larger than the parts alone..
1. The Intelligence of a Business
Date Published: July 15, 2024
Date Added: September 14, 2025
Summary
This essay explains why I first wanted to title the book, The Intelligence of a Business — emphasizing the enterprise as a living organism, not just a machine for storing data. It shows how BI, knowledge graphs, AI, and other tools fit together as parts of a single mind.
Placed early in the assemblage, this piece delivers the north star of the trilogy: a business can be intelligent, not just informed. It establishes the metaphor of the enterprise as an organism with organs (BI, KGs, process models, etc.) that work together. It signals to the reader that the book isn’t a recipe manual, but a conceptual reframing of what intelligence means at enterprise scale. This makes it the perfect framing piece — the rest of the essays are the “organs”, but this post is the statement of purpose.
Seeing the enterprise as an organism was only the beginning. To truly understand its intelligence, it wasn’t enough to know the structure of its organs; it was necessary to watch how they moved in time. That search for rhythm and sequence became the foundation for Time Molecules.
2. Sneak Peek at My New Book – Time Molecules
Date Published: March 14, 2025
Date Added: September 14, 2025
Summary
This essay introduces Time Molecules as the natural follow-up to Enterprise Intelligence. Where the first book explored how enterprises could be structured as intelligent organisms through BI and knowledge graphs, this second book moves into the realm of process and time. It frames time itself as a kind of molecule, with event streams broken into sequences that can be summarized and recombined into Markov models. The result is a way of making time analyzable at scale, showing how businesses don’t just store information but actually live through sequences of events that can be studied, optimized, and even anticipated.
The placement of this post in the trilogy is crucial. It marks the shift from structure to motion, from the skeleton of intelligence in Enterprise Intelligence to the lifeblood of time in Time Molecules. By framing processes as molecules of time, readers are given a way to see business not as a static intelligence but as a moving, adaptive system. That shift sets the stage for this third volume, where the focus is no longer just on the body or the flow, but on the full assemblage of reasoning, goals, and systems of thought that together create intelligence. In the overall arc of the trilogy, this essay reminds the reader where the story left off and why the next step — the assemblage — matters.
Once the body and its motion had been described, the next challenge was connection. Structure and flow needed to be fused into a single framework, one that could hold both the correlations of BI and the sequences of process. This search for unity gave rise to the Enterprise Knowledge Graph.
Tagged AI hidden markov model machine-learning OLAP cubes python
3. BI-Extended Enterprise Knowledge Graphs
Date Published: July 18, 2025
Date Added: September 14, 2025
Summary
This essay explains the conceptual bridge between Enterprise Intelligence and Time Molecules by introducing the Enterprise Knowledge Graph (EKG). The EKG combines the Tuple Correlation Web from the first book with the Markov process models of the second — effectively creating a knowledge graph that spans both structure and time. In doing so, it crafts a single framework reminiscent of “business spacetimes”, enabling event detection, semantic relationships, and temporal patterning to interweave. Using an “SBAR” (Situation, Background, Analysis, Recommendation) approach, the piece situates the EKG as a middle-path strategy—stable, evolutionary, and able to leverage the strengths of BI even as AI grows more central.
This essay serves as the introduction to the assemblage paradigm. It matters because it proves continuity: the first two books aren’t merely sequential—they form a layered foundation, and this essay is the keystone that unifies them.
This is the moment when the trilogy’s narrative shifts from foundation and flow into something more holistic. The EKG isn’t just a model—it’s the home into which reasoning, goals, causality, performance, and emotion will later be embedded. Here, the reader understands that the pieces built so far are not ends in themselves but the substrate of a richer, evolving form of intelligence.
With the bridge built, the trilogy had its spine. Yet even the strongest ideas depend on timing. As the industry entered signs of another AI winter, the need for grounded, durable approaches became clearer. That context sharpened the argument for Enterprise Intelligence and prepared the ground for the assemblage.
Tagged: AI Knowledge Graphs LLM
4. AI Winter, Good Timing for My Book
Date Published: July 19, 2024
Date Added: September 14, 2025
Summary
This is really what this volume is about. As I write this, there are the signs of Fall for this current AI summer. Much of it is due to LLMs reaching a point of diminishing returns on the core theory that drove this AI summer—the bigger the LLM the smarter it will be.
Discusses the timely release of Enterprise Intelligence amidst a potential AI winter, a period of reduced AI investment and hype. Asahara argues that this timing is ideal, as the book focuses on practical, sustainable applications of AI, specifically through integrating business intelligence, data mesh, knowledge graphs, and large language models. It emphasizes the TCW as a key framework for robust enterprise analytics, positioning the book as a guide for businesses to navigate AI challenges effectively during a downturn. The post suggests that the AI winter creates an opportunity for grounded, value-driven AI strategies, aligning with the book’s core themes.
Tagged: AI ai winter artificial intelligence ChatGPT LLM technology trough of disillusionment
5. Charting The Insight Space of Enterprise Data
Date Published: September 13, 2024
Date Added: September 14, 2025
Summary
This concise but powerful essay serves as an invitation to Enterprise Intelligence, framing its ambition and its foundation in enterprise-grade BI. I’ve positioned BI not merely as data repositories, but as the deterministic, curated, and trusted bedrock upon which transformative AI-driven enterprise intelligence can be built. I introduce the key structural ideas—namely the Insight Space Graph (ISG) and Tuple Correlation Web (TCW)—as tools that turn BI queries into a living ecosystem of insights. Instead of isolated dashboards, these constructs map inter-domain relationships automatically, unlocking connections that humans might never discover and even mitigating the need for synthetic. In essence, the essay imagines BI not as passive reflection but as active, discovery-driven intelligence.
From there, the conversation turned outward. Presenting these ideas at DMZ 2025 offered a chance to connect them with a broader audience, and to show how knowledge, once cached in graphs, could anchor intelligence even as LLMs stretched context and scale.
Tagged: AI business intelligence Large Language Models synthetic data
6. Key Takeaways from My Two Upcoming DMZ 2025 Sessions
Date Published: February 21, 2025
Date Added: September 14, 2025
Summary
At its core, this post emphasizes that knowledge is a cache—a durable, shareable form of intelligence that we preserve outside of our minds. I explore how we encode knowledge: through our brains, teaching, art, text, code, and modern tools like LLMs and knowledge graphs. Knowledge graphs stand out because they are:
- Deterministic: authored, structured, and controlled.
- Symbiotic with LLMs: while LLMs learn probabilistically, these graphs offer precision and clarity—a design complement, not a competitor.
The post also flags a caution: don’t hand AI the keys too hastily. LLMs, while powerful, still misinterpret nuance, obscure ambiguity, or lack a firm grasp of flawed training data. Relying solely on them—especially in unpredictable, ambiguous contexts—is risky. Traditional BI remains trustworthy and essential.
The overarching message is one of strategic synthesis: real enterprise intelligence arises when:
- Knowledge graphs provide curated, enduring context.
- LLMs assist with breadth and pattern discovery.
- BI—with its structure, domains, and trusted data—anchors the system.
This synergy allows organizations to cache lessons, extend insights, and scale understanding in ways neither method achieves alone.
Tagged: abductive reasoning data modeling zone 2025 dmz 2025
7. The BI Counterpart to Infinite Context
Date Published: November 21, 2024
Date Added: September 14, 2025
Summary
This essay draws a compelling parallel between AI’s “infini-attention” mechanisms — which allow models to handle effectively “infinite context” by compressing and retaining only essential information — and BI architectures like the TCW, ISG, and cubespace. The crux: both domains need to manage massive amounts of data without being overwhelmed. In the AI world, infini-attention keeps models focused and efficient; in BI, curated semantic layers (like TCW and ISG) maintain actionable, retrievable insights that can scale and persist.
Tagged: AI LLM rag technology
Closing to Part I
The opening part of this book has traced the lineage of the trilogy—first the organism of Enterprise Intelligence, then the temporal flows of Time Molecules, and finally the bridge that joins them. These essays show why a grounded foundation matters, especially as the industry faces the cooling winds of another AI winter. They leave us at the threshold of the deeper inquiry: if enterprises can be seen as organisms that move in time, what, exactly, constitutes their intelligence? To answer, we must descend to the foundations—to reasoning itself, the raw material from which all higher forms of intelligence (including the artificial ones) are assembled.
Part II – The Foundations of Intelligence
The first step in examining the foundations of intelligence is to understand how organizations climb the ladder of analytic capability. Before we can speak of reasoning, we must see how data itself is harnessed—moving from description to prediction, and eventually to prescriptions that shape outcomes.
- Simple, robust, iterative, intelligence, and decoupled recognition and action.
- Inductive, deductive, and abductive reasoning.
1. Analytics Maturity Levels and Enterprise Intelligence
Date Published: July 10, 2024
Date Added: September 14, 2025
Summary
Explores the relationship between analytics maturity levels and the concepts presented in Enterprise Intelligence. It outlines how organizations progress through analytics maturity stages—descriptive, diagnostic, predictive, and prescriptive—and how Enterprise Intelligence leverages the Tuple Correlation Web (TCW) to advance enterprises toward higher maturity. The book integrates business intelligence, data mesh, knowledge graphs, and large language models to enable sophisticated analytics, helping organizations move from reactive data use to proactive, predictive, and prescriptive decision-making. The post emphasizes that the TCW provides a structured framework to correlate data across these stages, enhancing enterprise decision-making and intelligence.
If maturity models show us the rungs of enterprise capability, Bloom’s Taxonomy reminds us what kind of thought climbs those rungs. This is where data scaffolding meets cognitive scaffolding, shifting the conversation from the mechanics of analytics to the nature of reasoning itself.
Tagged: abductive reasoning AI bi levels of maturity data-science enterprise knowledge graph machine-learning proscriptive analytics
2. Exploring the Higher Levels of Bloom’s Taxonomy
Date Published: June 24, 2024
Date Added: September 14, 2025
Summary
This essay bridges human and machine reasoning by reframing Bloom’s Taxonomy—traditionally an educational hierarchy—as operational modes for enterprise AI. It invites BI analysts to stretch beyond reporting data to embrace deeper modes of thought: inductive, deductive, and abductive reasoning, all supported by structures like the Enterprise Knowledge Graph (EKG).
Here, the trilogy steps into cognitive architecture. Having laid out how analytics maturity ladders up through structural and temporal models, this essay asks: What kind of reasoning makes that intelligence possible? It elevates the discourse from data frameworks to reasoning frameworks, preparing the reader to see data not just as patterns, but as arguments and inferences. It sets the logical stage for the next essay, where thought moves toward meaning—not just pattern detection but insight into cause.
Reasoning, however, does not live in abstraction alone. It must contend with evidence—messy, imperfect, and often misleading. The discussion of Bloom’s higher modes prepares us to ask not only how we reason but how well. That question leads directly to correlation, a first foothold in the larger terrain of causation.
Tagged: abductive reasoning artificial intelligence bloom’s taxonomy deductive reasoning enterprise knowledge graph inductive reasoning
3. Correlation is a Hint Towards Causation
Date Published: August 8, 2024
Date Added: September 14, 2025
Summary
This essay warns against mistaking correlation for causation, acknowledging that simple techniques like Pearson correlation can mislead. Yet rather than reject correlation outright, it reframes it as a necessary first indicator—a cue to deeper exploration through conditional probabilities, human and AI-derived scoring, or even formal modeling. The message: correlation is not a conclusion but a prompt to inquire further.
In the larger arc of Foundations of Intelligence, this piece transitions from reasoning frameworks into the realm of inference and validation. Correlation is shown not as a scientific endpoint, but as a signpost that guides logical and probabilistic inference—linking back to abductive reasoning. By treating correlation as a starting point rather than a finish line, the essay primes the reader for richer discussions of causality, strategy, and system response—which naturally lead into the next chapters about goal-setting, performance, and emotional intelligence in systems.
Tagged: abductive reasoning
Closing to Part II
The foundations of intelligence show us what enterprises can do with data and how they begin to reason with it. Maturity models reveal the stages of capability; Bloom’s hierarchy reframes those stages as modes of thought; and the discussion of correlation reminds us that reasoning must always be tested against evidence. Together, these essays establish the raw materials of intelligence—the scaffolding of analysis, reasoning, and inference. But intelligence is never neutral. It is always directed, always striving toward something. The very act of reasoning only matters if it shapes action, and action requires purpose.
Part III – Artificial Goals and Feelings
Intelligence cannot be understood as perception and reasoning alone. At some point, it must turn outward, define what it wants, and move the world in that direction. That turn introduces the machinery of goals. An intelligent system does not simply describe its environment; it sets objectives, tolerates risks, and decides which sacrifices can be endured to reach a desired state. With those choices come the emotions of systems—pain when tolerances are crossed, satisfaction when thresholds are met, urgency when outcomes slip away.
In enterprises, this is the terrain of performance management. Metrics and KPIs are not neutral measurements; they are the signals of aspiration and distress, the language of organizational feeling. Predictive analytics gives those signals foresight, transforming strategy maps into guides that explain not only what is happening but why. Pain thresholds mark the limits of endurance, and optimization methods test how far those limits can be stretched without breaking. Correlation scores stand watch over fragile assumptions, alerting us when the world no longer behaves as we believed it would. Even the mapping of KPI relationships, whether through early manual diagrams or modern LLM-assisted graphs, reflects the same pursuit: to see how goals interlock, how one decision propagates through a system, and how intelligence can act with awareness of consequence.
Here, intelligence acquires intention. It is no longer content to observe and reason. It begins to want, to strive, to feel the weight of its choices.
Many of these KPI topics are covered in Enterprise Intelligence. But I include these essays because intelligence is meaningless without goals and the wisdom to make clever trade-offs.
1. Bridging Predictive Analytics and Performance Management
Date Published: August 31, 2010
Date Added: September 14, 2025
Summary
This post argues that the next powerful evolution in business intelligence is not just collecting metrics—it’s strategic diagnosis. Predictive analytics brings strategy maps to life by enabling “why” and “how” rather than just “what.” Traditional balanced scorecards and strategy maps identify what’s going wrong but don’t assist with fixing it. The essay champions a bridged model where predictive models validate, weight, and inform cause-and-effect relationships—making performance management proactive, dynamic, and far more intelligent. The example of using Predictive Analytics to model fees and patient behavior illustrates how the strategy map becomes an active, predictive roadmap rather than a static dashboard.
Tagged: performance management strategy map
2. Levels of Pain: Refining the Bad Side of KPIs
Date Published: January 5, 2014
Date Added: September 14, 2025
Summary
Every action toward a goal involves trade—time, money, reputation: these are investments of effort, risk, and energy. In this post, I reframe what we typically call “pain” not as a purely negative outcome, but as meaningful sacrifice and information. Instead of portraying KPI status on a simple “bad-to-good” continuum, I introduce threshold-based stages of pain, each triggering real consequences:
- Warning (pink): Early deterioration—think tire tread wearing—manageable, offering leeway.
- Pain (red): The system begins to stress—like a popped tire—still operable, but precarious.
- Major Pain (maroon): Deeper failure—tire off the rim—the system still moves, but with sparks.
- Broken (black): System halt—complete failure, like a broken axle.
I translate this metaphor into business terms—missed deadlines, cash flow disruption, layoffs, and organizational collapse. Importantly, these aren’t just static risk categories; they’re investments that enterprises knowingly endure (Warning) to avoid compounding failure. This structured awareness enables better prioritization and decision-making.
I also introduce Just Right Targets, a smart Monto Carlo-style optimization method: define the pain threshold you’re willing to tolerate, simulate variables in a what-if scenario, and use an algorithm (like a genetic algorithm) to identify configurations that avoid exceeding those thresholds—all while meeting objectives without pushing into irrecoverable pain.
Tagged: kpi performance management strategy map
3. The Effect Correlation Score for KPIs
Date Published: December 2, 2013
Date Added: September 14, 2025
Summary
This essay introduces the Effect Correlation Score (ECS)—a metric for validating whether supposed cause-and-effect relationships between KPIs still hold true. Rather than relying solely on targets, statuses, or trends, ECS uses techniques like Pearson correlation to measure if a KPI’s progress meaningfully correlates with other outcomes. The post warns against blind adherence to strategy when those underlying correlations have decayed due to shifting context, competitor responses, or stochastic noise. It also cautions against the transference of cost—the illusion of improvement created when gains in one KPI merely shift burdens elsewhere, rather than delivering real progress. ECS acts as a dynamic loyalty check on assumptions, prompting adjustment when patterns no longer lead to outcomes.
Building on the need to engage reasoned thought (via Bloom’s hierarchy) and test causal inference (through correlation), this essay strengthens the scaffolding of intelligent systems by ensuring strategies remain valid in a changing environment. ECS isn’t just a tool for analysis—it is a sentinel, scanning the integrity of tactical links as strategies play out.
Having established the Effect Correlation Score as a real-time guardrail—validating whether KPIs truly reflect the assumptions we make—it’s natural to ask how these relationships can be mapped and maintained at scale. Just as ECS exposes when cause-and-effect breaks down, a broader view is needed to surface where progress in one KPI may hide a transference of cost into another. That next step is the KPI Status Relationship Graph, updated for the era of machine reasoning.
Tagged: cause and effect correlation kpi performance management strategy map
4. KPI Status Relationship Graph Revisited with LLMs
Date Published: June 18, 2023
Date Added: September 14, 2025
Summary
In this essay, I return to a concept I first introduced in 2006: a graph that maps the formulas and parameters behind KPI statuses. At the time, implementing that idea was far too labor-intensive. But now, with tools like Neo4j for graph data and LLMs like ChatGPT (or Azure OpenAI), the idea comes alive. LLMs can parse KPI formulas, even when expressed in different languages, and automatically assemble a KPI Status Relationship Graph (KSR)—a dynamic, evolving map of interdependencies. In practical terms, you can feed the KPI formulas into the model, and it will help you build and maintain a graph representing how metrics influence one another. This isn’t just documentation—it’s co-authoring with a broadly knowledgeable assistant that can keep your strategic reasoning current.
From the modern, AI-driven reinvention of the KSR, it’s worth turning back to the roots of the idea: the original Cause and Effect Visio Graph. Where the KSR uses LLMs and graph databases, this earlier work approached the same goal—mapping KPI relationships—from a modeling perspective, before today’s tooling existed.
Tagged: strategy map performance management kpi neo4j ChatGPT LLM kpi status AI ontologies
5. KPI Cause and Effect Visio Graph
Date Published: March 12, 2006
Date Added: September 14, 2025
Summary
Originally posted in 2006, this essay preserved as faithfully as possible shows an early attempt to visualize the interdependencies of KPIs using Visio and SQL Server Analysis Services. The idea: extract a graph of relationships from BI models—perspectives, KPIs, calculated measures—and render it visually so analysts understand the consequences of changing any metric. The effort was symbolic—manual, brittle, but pioneering. It laid the groundwork for what later became automated and dynamic via LLM-assisted graph generation. In essence, this old Visio graph marks the origin of today’s intelligent KPI modeling, before the tools were ready.
Tagged: kpi performance management
Closing to Part III
In this part, performance management became more than a method for reporting progress. It emerged as the place where intelligence develops intention. Predictive analytics bridged strategy and diagnosis, transforming scorecards from passive dashboards into living maps of cause and effect. Pain was reframed not as failure but as structured sacrifice—an enterprise’s willingness to endure stress in pursuit of its objectives, bounded by thresholds and tested by simulation. The Effect Correlation Score reinforced this vigilance, guarding against the erosion of assumed relationships and reminding us that strategies can decay as quickly as they are formed. From there, the conversation turned to graphs: first the modern, LLM-assisted mapping of KPI interdependencies, then the older, hand-drawn attempts that foreshadowed it. Together they tell a story of continuity—of enterprises groping for ways to see how goals ripple across a system, and of tools catching up to make that vision possible.
With these essays, goals and feelings become explicit parts of the assemblage. Intelligence now has a pulse: it sets objectives, feels pain, checks its assumptions, and visualizes the web of consequences that bind its choices. Having reached this point, the next step is to see how these goal-driven systems interact with other forms of reasoning and structure, completing the assemblage that allows an enterprise to think, adapt, and act as a whole.
Related blogs on my Kyvos blog page:
Part IV – The Data Processing of Sentience
Wisdom does not arise from data alone. It emerges when data is carried forward through process, sensed in detail, and connected by imagination. This trilogy of essays that follow trace that journey. The first reframes the familiar DIKW ladder as a living current, showing that intelligence comes not from the storage of facts but from the ability to move through them in sequence, to model causality, and to anticipate what comes next. The second widens perception, reminding us that intelligence depends on resolution—the thousands of senses, human or artificial, that provide the granularity from which awareness is built. The third lifts perception into creativity, showing how curiosity stitches distant experiences together through analogy, producing original thought.
Together, these stories reveal a simple moral: intelligence is not a warehouse of knowledge but a rhythm, a sensitivity, and a leap. It is process made aware, perception made rich, and imagination made bold. This is the beginning of sentience—the moment when information ceases to be stored and instead becomes lived, felt, and re-imagined.
1. From Data Through Wisdom: The Case for Process-Aware Intelligence
Date Published: May 30, 2025
Date Added: September 14, 2025
Summary
This essay reframes the traditional DIKW hierarchy—Data, Information, Knowledge, Wisdom—into something living and temporal. Rather than a static pyramid of abstractions, it invites us to think of wisdom as something built through process-aware movement—a flow modeled via Hidden Markov Models and Bayesian networks. The message: intelligence is not about capturing snapshots but about modeling sequence, causality, and anticipation.
In this framework, modern AI techniques—including ML, LLMs, and knowledge graphs—have conquered the first levels (data, information, knowledge), but the domains of understanding and wisdom remain the exclusive terrain of human intelligence. To bridge that gap, Enterprise Intelligence introduced constructs like the ISG and the TCW, and Time Molecules scales those into systems of temporal process. The essay isn’t a step forward in abstraction; it’s a dimensional leap—like moving from Flatland into three-dimensional insight. Importantly, it insists that AI should augment, not replace, human agency—making humans smarter, not obsolete.
Tagged: AI ChatGPT LLM markov models process mining systems thinking technology
2. Thousands of Senses
Date Published: June 15, 2025
Date Added: September 14, 2025
Summary
In this post, I explore the cliché of the “five senses” and point to the reality: both humans and AI systems rely on thousands of granular sensory streams. Just as millions of rods and cones in the retina capture nuanced visual data, enterprises would benefit from sensing myriad micro-signals—not only core KPIs but edge-level, high-resolution event streams. This sensory depth shifts awareness from sketchy outlines to vivid, real-time representations. I argue that AI’s current intelligence model falls short without this sensory richness, and that real awareness comes from embracing fine-grained, continuous streams—the pulse of a dynamic system, not its snapshot.
Adding “Thousands of Senses” into Part IV enriches the chapter’s thesis: intelligence is not just structure or flow—it is perceptual richness. Having framed intelligence as a process in From Data Through Wisdom, this essay expands that view into the sensory dimension: wisdom isn’t only built over time, it’s nourished with high-fidelity data streams. Just as living brains interpret depth from detail, enterprises must broaden their sensory intake to capture reality as it unfolds.
Tagged: AI artificial intelligence ChatGPT LLM technology
3. Analogy and Curiosity-Driven Original Thinking
Date Published: June 27, 2025
Date Added: September 14, 2025
Summary
In this essay, we’ll turn creativity into a process. Original thinking isn’t conjured from nothing—it’s woven from analogies that connect distant domains: Zen koans with surgical protocols, poems with factory lines. These analogies, elevated to “Time Molecules”, become procedural graphs—each node an event, each edge a probability. Faced with a new challenge, intelligence maps the current state and desired future onto this graph, and with the help of LLMs, traces a probabilistic path forward. In essence, creativity becomes the recombination of processes, not just metaphors.
This essay crowns Part IV by showing how sentient intelligence emerges through connection. After establishing perception (via process and sensory streams), this post demonstrates how those sensations can be woven into new patterns. Analogy and curiosity transform data flows into creative action—they are the spark of original though
Tagged: AI ChatGPT philosophy
Closing to Part IV
These three essays reveal intelligence not as a storehouse but as a living current. First, it acquires rhythm through process, learning to anticipate what comes next. Then, it gains depth through thousands of senses, perceiving the world in higher resolution. Finally, it discovers creativity through analogy and curiosity, weaving connections across distant domains to imagine what has never been. Together, they sketch the beginnings of sentience: awareness that flows, perceives, and invents.
With process, perception, and imagination in place, intelligence is no longer only a system that knows. It becomes a system that feels its way forward. The next step is to ask how such systems act with intention, how they pursue goals, and how they bear the weight of consequence. That is where the assemblage turns next.
Part V – Graph Structures Beyond Ontologies and Taxonomies
Taxonomies and ontologies name the world, but they do not make it move. These essays show what lies beyond: dynamic graphs that capture orientation, decision, feedback, and consequence. From OODA loops to trophic cascades, from strategy maps to KPI networks, we see enterprises not as static catalogs but as living ecosystems of influence. Graphs become the backbone of intelligence—contextual, causal, and ready for reasoning.
We’ve already discussed other structures such as the ISG, TCW, and KPI structures.
1. Beyond Ontologies: OODA & Knowledge Graph Structures
Date Published: March 14, 2025
Date Added: September 14, 2025
Summary
I turn the OODA loop into a machine-traversable knowledge graph: Observe is grounded in the data catalog and event streams; Orient is modeled with trophic cascades to capture ripple effects; Decide uses strategy maps with Bayesian reasoning and Markov models; Act is workflows plus feedback that closes the loop. The point is an authored (controllable) KG that encodes human reasoning patterns so both people and AI can navigate decisions—not just look up facts. The post originated from my DMZ 2025 session and is explicitly written to be used as an LLM prompt.
Having embedded OODA in the KG, the next question is how to do Orientation well. This is where trophic cascades step in: they give Orientation a rigorous shape, converting raw observations into propagating consequences that later inform Decision (strategy maps, Bayesian/Markov) and calibrate Action/feedback. In short, Part 2 supplies the causal lens that Part 1 needs between Observe and Decide.
Tagged: AI hidden markov model Knowledge Graphs lqm NFA ontology OODA Loop strategy map taxonomy trophic cascade
2. The Trophic Cascade of AI
Date Published: January 31, 2025
Date Added: September 14, 2025
Summary
I introduce trophic cascades (Paine’s starfish and the otter–urchin–kelp examples) as a clear causal template for orientation, then apply it to AI: a disruption (ex. DeepSeek R1) propagates across producers and consumers (OpenAI, Microsoft, Nvidia, TSMC, markets), illustrating how influence flows through an ecosystem. I note it’s “trophic” by analogy—really an influence/causal network—and explore alternative shocks (ex. TSMC or policy) to show how the graph helps reason about second- and third-order effects.
Tagged: AI artificial intelligence ChatGPT LLM trophic cascade
Closing for Part V
Taken together, these essays move beyond static taxonomies/ontologies to a living decision graph. The OODA-embedded KG provides the scaffold; trophic cascades supply the causal currents for Orientation; strategy maps + Bayesian/Markov give Decision its quantitative backbone; workflows + feedback operationalize Action. Alongside the ISG, TCW, and KPI networks I’ve already introduced, this forms an authored, explainable substrate that LLMs can read as prompts and humans can trace as rationale—an enterprise graph that doesn’t just name the world; it makes it move.
Part VI – Machine Learning in the LLM Era
Here begins a deeper journey into the era shaped not just by large language models, but by the intelligent choreography of models within meaningful structures and the conscious sacrifices that fuel innovation. Part VI explores how intelligence must balance risk and reason: creativity demands discomfort, and learning demands orchestration. We’ll begin by revisiting what it looks like when thought reaches beyond boundaries, and then discover how even the most powerful models gain structure and purpose when embedded within knowledge graphs.
1. Thinking Outside of the Box is About Sacrifice
Date Published: August 18, 2025
Date Added: September 14, 2025
Summary
This essay reframes the act of creativity as an act of strategic discomfort. Using the classic nine-dot puzzle as a metaphor, I show that breakthroughs require pushing—and often sacrificing—comfort. Drawing parallels to chemotherapy’s painful path to health, I argue that design and innovation demand calibrated risk. I further reflect on how LLMs lack that existential sense of sacrifice; they optimize without feeling. True ingenuity arises when systems—or creators—are structured to bear pain not as failure but as measured investment.
Before models can be embedded into systems, they must emerge from creative risk. Sacrifice widens the possibility space. Now, we turn to structure: how do we place machine learning models into frameworks that multiply their intelligence while keeping them legible and manageable?
Tagged: AI artificial intelligence data science LLM support vector machine
2. Embedding Machine Learning Models into Knowledge Graphs
Date Published: January 9, 2025
Date Added: September 14, 2025
Summary
Here, the metaphor of neurons transforms into an implementation blueprint. Knowledge graphs become ecosystems—not loose clouds of nodes—but structured forests of meaning. I propose embedding lightweight, “mini-NN” models directly into these graphs as functional nodes, each with purpose, modularity, and context. These embedded models—whether simple rules, classifiers, or pointers to larger models—grant knowledge graphs self-assembly, adaptability, and clarity. Rather than a monolithic LLM, this hybrid emerges as a distributed, interpretable system, where semantics and statistical learning augment each other.
Now we’ve seen the emotional root of invention and the structural frame that carries it. What results is intelligence that doesn’t just compute—it feels poised, organized, purposeful.
Tagged: AI artificial intelligence ChatGPT data modeling intelligent systems knowledge graph applications LLM machine learning integration
3. Reptile Intelligence: An AI Summer for CEP
Date Published: September 28, 2025
Date Added: September 28, 2025
Summary
For decades, Complex Event Processing (CEP) sat in the shadows—known in BI as “streaming insight” or “plumbing,” but rarely recognized as AI. At the worm level of intelligence, CEP was about a few dozen regex-like rules: reflexes, quick and useful, but shallow. Scaled up with platforms like Flink, CEP plays the role of “reptile intelligence”. Thousands of rules and recognizers firing in parallel, inhibiting, reinforcing, and recombining, form a recognition fabric that looks a lot like the substrate of cognition.
This essay argues that CEP is one of the missing AI components—not the brain itself, but a core piece. Just as Markov models are the pre-aggregations that make BI charts possible, CEP is the recognition substrate that larger reasoning systems, from Prolog to LLMs, can build on. What never had its “AI summer” now deserves the AI summer of Complex Event Processing.
Tagged: assemblage of AI CEP complex event processing event driven architecture flink petri nets process mining systems thinking nollm not only llm
4. Stories: The Unit of Human-Level Intelligence
Date Published: October 10, 2025
Date Added: October 10, 2025
Summary
This essay argues that the fundamental transaction of human intelligence is the story: compact, transmissible bundles that carry context, motive, causality, and lessons. It traces how the brain keeps a running “story workspace”—from confabulation and the left-hemisphere interpreter to the default mode network—and how sleep and curiosity help revise unfinished narratives. The piece then pivots from cognition to engineering: if strategy is a special kind of story about changing outcomes, we should encode stories as graphs that can be queried, compared, and improved. The proposed stack uses a strategy map as the visual spine, SBAR as the disciplined speaking order (S/B/A/R), and RDF/Turtle + OWL + SPARQL to serialize and govern the story so it can dock to an Enterprise Knowledge Graph. Worked examples (e.g., the ginger that finally bloomed) show how LLMs can translate between narrative and graph, with guardrails like “only R introduces new causal links.” The result is a practical protocol: turn the stories leaders tell into auditable, computable assets that can be diffed, linked, and re-told with evidence.
Tagged: abductive reasoning Knowledge Graph nollm not only llm strategy map
5. Context Engineering
Date Published: October 18, 2025
Date Added: October 18, 2025
Summary
This chapter frames context engineering as the discipline required to make distributed AI systems operate coherently and predictably. It extends the principles of Enterprise Intelligence and Time Molecules into real-time coordination across specialized AI agents—each fine-tuned for its own domain but dependent on clear communication and shared context. Drawing from Agile, the AI Agent Scrum analogy illustrates how teams of agents coordinate through structured, minimal communication—each reporting its needs, progress, and dependencies rather than over-communicating.
The first pillar of context engineering focuses on deciding context as you go—using context contracts that specify what each workflow state needs and provides, keeping context windows small and deliberate. Here, Markov Models and Non-Deterministic Finite Automata (NFAs) are used to represent real operational workflows, transforming statistical transitions into explicit contracts for data hand-offs. Time Molecules bring foresight to these workflows, guiding prefetching and anticipating downstream requirements.
The second pillar builds the enterprise-wide context foundation—drawing from the EKG, TCW, ISG, and pre-aggregated OLAP structures of Enterprise Intelligence. These provide fast, governed access to curated data so that agents reason over clean, validated information rather than unstructured noise.
Together, these pillars make AI systems behave more like well-run teams: each agent specialized, context-aware, and auditable, operating with the same discipline that Agile brought to software development—clear ownership, lightweight coordination, and continuous feedback.
Tagged: artificial intelligence context engineering
Closing for Part VI
In this part, the intelligence of the LLM era is reframed. Creativity no longer means burning bridges—it requires measured sacrifice. Models no longer exist as opaque monoliths—they must be woven into structured graph ecologies for meaning and maintainability. Together, these essays argue for intelligence that is courageous—and composable. What follows is the ultimate challenge: how do we align such systems with structures of purpose, scale, and responsibility to complete this assemblage?
Part VII – Prolog in the LLM Era
Rules are system-level definitions. The problem is that whatever systems we develop are prone to entropy (the parts wear down) and constant changes outside of it (the assumptions it was built under are different).
Prolog (and Lisp) are the icons of one of the prior AI hypes— the “Expert Systems” of the 1980s and 1990s, along with Japan’s “5th Generation” effort.
What role does logic still play in an era dominated by large language models? This series of essays explores deductive reasoning, rule-based systems, and the strange synergy between Prolog and LLMs. The result is a dialogue between symbolic and statistical AI, showing how each fills the gaps of the other.
1. Does Prolog Have a Place in the LLM Era?
Date Published: August 4, 2024
Date Added: September 14, 2025
Summary
This essay asks a fundamental question: in an age dominated by Large Language Models, can Prolog—once the backbone of expert systems—still contribute meaningfully? I point out that Prolog KBs are explicitly programmed—internalized, human-authored rules that are deterministic and traceable—while LLMs are trained from vast text and inherently opaque. Through a deft classroom analogy, I contrast how deterministic systems always behave as designed (“They do exactly what I told them to”), while LLMs may appear robust yet unpredictably so.
By resurfacing my own early Prolog interpreter (“Soft Coded Logic”) built in 2004, I underscore Prolog’s enduring strengths: precision, efficiency, and clarity. I explore real-world capabilities and limitations of Prolog in modern contexts, and even test Prolog-style reasoning side by side with ChatGPT—highlighting how LLMs can lose logic even with “think like a Prolog interpreter” prompts.
I also acknowledge the appeal of Knowledge Graphs (RDF/OWL) and Machine Learning in my book’s architecture. While Prolog didn’t fit within the book’s scope, exploring it here offers insight into rule-based precision versus the fuzzier, but richer, inference of LLMs.
In the Chapter 1, the key question was whether Prolog still has a place in a world captivated by LLMs. That opened the conversation—next, in Chapter 2, I explore exactly how they can coexist and reinforce each other, turning Prolog not into a relic, but into a bridge between rule-based clarity and the inferential power of LLMs.
Tagged: abductive reasoning artificial intelligence Large Language Models prolog prolog ai agents
2. Prolog AI Agents
Date Published: August 7, 2024
Date Added: September 14, 2025
Summary
This essay builds upon the case made in Chapter 1 by exploring how Prolog can play a meaningful, modern role—especially when paired with LLMs. I revisit my Prolog variant, SCL, and reflect on early goals: decoupling logic from procedure, managing expert knowledge via maintainable rule bases, and enabling cross-context decision-making in enterprises. Although authoring complete knowledge bases in Prolog remained daunting, LLMs offer a new opportunity: they can assist with rule discovery, refinement, and even draft rule creation from natural language. This creates a “golden copy” of vetted logic.
Crucially, I argue that Prolog rules can serve as a cache for LLMs—traceable, transparent, and reusable—unlike the opaque weight distributions of neural networks. Whether authored by experts, refined with LLMs, or drawn from machine-learned models, these rules gain consistency and clarity. The essay closes with a design vision: lightweight Prolog snippets as functional artifacts, able to be mixed, updated, and deployed like microservices—and carrying the promise of democratized, expressive, verifiable intelligence.
In Chapter 2, we envisioned Prolog as a declarative, LLM-enhanced knowledge cache—compact, transparent, and effective. But vision without action is hollow. That drives us into Chapter 3: the practical setup, the environment in which logic gets coded, tested, and integrated. Here, theory becomes something you can run—and modify—with your own hands.
Tagged: ai agent LLM prolog prolog ai agents retrieval augmented generation
3. Playing with Prolog
Date Published: August 12, 2024
Date Added: September 14, 2025
Summary
In this installment, we shift from theory to practice, walking readers step-by-step through installing and using SWI-Prolog together with pyswip in Python. I acknowledge Prolog’s niche status, noting that environments like this require caution—but also assert that they remain reliable options in a modern context.
Throughout the post, I provide context: why Prolog—even in 2024—still matters, and how its role is not to replace LLMs or Knowledge Graphs, but to complement them with precision, structure, and logic. The hands-on guidance aims to reduce friction for those curious about integrating deterministic reasoning engines into today’s AI workflows.
In Chapter 3, the focus was on getting Prolog running in a modern environment—proving that the logic engine still works today. That foundation prepares us for what comes next: enriching Prolog’s power with inference from data. In Chapter 4, theory meets practical fusion: we begin turning models into rules, making Prolog not just usable, but dynamically insightful.
Tagged: artificial intelligence LLM prolog pyswip swi-prolog vector database
4. Prolog and ML Models
Date Published: August 15, 2024
Date Added: September 14, 2025
Summary
In this installment, the conversation evolves deeper: now we explore how Prolog can partner not just with LLMs, but with machine learning models. These models—think decision trees, clustering, association rules, and logistic regression—occupy a “Goldilocks” zone between the fuzzy generality of neural nets and the rigid determinism of code.
I walk through an example using a Decision Tree trained on the Iris dataset in Python, transforming its logic into Prolog rules via a script. This translation demonstrates interpretability without sacrificing flexibility—Prolog becomes a human-readable layer over probabilistic models. Validation shows the Prolog representation produces the same predictions, blending clarity with yield. The takeaway: ML-derived rules distilled into Prolog enable systems that are both adaptive and auditable—empowering expert systems with data-driven evolution.
In Chapter 4, Prolog embraced the outputs of machine learning—models transformed into interpretable rules. That gave us clarity. Now, in Chapter 5, Prolog reaches into live business systems. It imports facts from OLAP/OLTP sources, synthesizes ML insights, and recombines them into logical reasoning about enterprise behavior. What was previously theoretical becomes not only context-aware, but operational.
Tagged: artificial intelligence LLM prolog pyswip swi-prolog
5. Prolog and Business Intelligence
Date Published: August 19, 2024
Date Added: September 14, 2025
Summary
In this chapter, I elevate the conversation by integrating Prolog into the heart of enterprise systems: OLAP and OLTP databases. I introduce MetaFacts—dynamic Prolog facts derived from curated OLAP/OLTP data—as well as MetaRules, expanding recall to include logic derived from ML models and human input. Through a Python-based walkthrough, I demonstrate how to generate Prolog facts from SQL queries (ex. using AdventureWorksDW data) and combine them with logical rules that detect high-value or repeat customers. I even show how complex BI mechanisms like calculated measures (ex. profit margin via MDX or DAX) can be translated into Prolog, especially with the help of LLMs. The result is a distributed, adaptive inference system: Prolog becomes a bridge between transactional data, analytics, and logic-based reasoning—providing scalable, transparent intelligence rooted in real-time business context.
In Chapter 5, Prolog moved from rule integration with BI systems into a dynamic intelligence layer—fact bases linked to business realities. That laid the behavioral groundwork. Now, in Chapter 6, we explore how that behavior becomes intentionally layered—moving from reflex to reasoning, from recognition to action. We step into a hierarchy of intelligence where logic is not simply executed, but orchestrated.
Tagged: artificial intelligence prolog
6. Four Levels of Intelligence
Date Published: August 21, 2024
Date Added: September 14, 2025
Summary
This chapter draws an elegant parallel between biological intelligence and AI by defining four ascending levels: Simple, Robust, Iterative, and Decoupled Recognition & Action. Simple recognition mirrors reflexive responses—like an insect darting from danger. Robust recognition involves combining signals—multiple conditions trigger recognition. Iterative recognition resembles the scientific method—forming hypotheses, testing them, and refining understanding. Finally, decoupled recognition separates perception from response—choosing actions based on context, awareness, and consequence.
I show how each level can be modeled in Prolog: straightforward rules for simple reflexes, compound logic for robust classifications, recursive queries for hypothesis testing, and conditional action-selection for decoupled decision-making. By embedding this structured logic within LLM-augmented ecosystems, I demonstrate how intelligence becomes not only reactive, but strategic.
In Part 6, I mapped a hierarchy of cognition—from reflex to recognition to strategic action—using Prolog as a model of layered intelligence. Next, in Part 7, the landscape expands. It’s no longer just about what logic can do, but how it interacts with broader knowledge infrastructure. This chapter bridges that gap: it asks not just how Prolog reasons, but how it can integrate with KGs to shape richer, more resilient AI systems.
7. Knowledge Graphs vs Prolog
Date Published: August 26, 2024
Date Added: September 14, 2025
Summary
In Chapter 7 we examine the juxtaposing of Prolog and Knowledge Graphs (KGs)—two approaches that often seem overlapping in reasoning systems. I explore their relative strengths: KGs excel at structuring knowledge via ontologies; Prolog shines at logical deduction, backtracking, and rule-based inference.
I call attention to their complementary roles: while KGs offer semantic structure and scale, Prolog delivers precision and dynamic logic. I argue for a hybrid approach—using modular Prolog snippets embedded within KG-supported systems—to achieve both clarity and depth. I also explain my tooling choice in Enterprise Intelligence, favoring Neo4j as a practical, accessible graph database, while acknowledging that Semantic Web tools like Stardog remain relevant. Ultimately, I position Prolog not as redundant but as a powerful complement to KGs in LLM-era intelligence architectures.
In Chapter 7, we positioned Prolog as a precision tool knitted into Knowledge Graph systems, bridging semantics with deterministic reasoning. Now, with “Deductive Time Travel”, we take the next logical step: not just integrating logic, but preserving and replaying its history. Intelligence becomes not only formalized, but archival—capable of reaching backward, learning, and adapting from the past.
Tagged: artificial intelligence enterprise knowledge graph prolog
8. Deductive Time Travel
Date Published: November 10, 2024
Date Added: September 14, 2025
Summary
This chapter reframes the value of Prolog through the lens of historical context—what I call “time travel in data.” Rather than simply executing logic, Prolog allows us to preserve decision-making snapshots, capturing rules as they were in specific moments (including the contextual rationale behind them). These snapshots, like model versioning or data timestamps, help AI systems understand not just what was decided, but why—enabling reasoning that is contextually anchored and historically informed.
I argue that embedding Prolog within LLM and Knowledge Graph ecosystems enriches intelligence by layering proven past logic—authored by experts—with contemporary, flexible models. Rather than pressing forward without reflection, AI gains depth by drawing on the wisdom of layered historical decisions. The essay also underscores the importance of human knowledge workers: the systems should be designed to accept, preserve, and reconsider expert-authored logic—not just automate forward decisions.
In this chapter, Prolog helped us preserve how decisions were made, capturing the logic of the past through “Deductive Time Travel.” Chapter 9 turns that logic into living strategy—bringing Prolog into systems that reflect organizational goals, fears, and beliefs. From preserved decisions, we move into active strategy mapping—Prolog as the engine of enterprise theory of mind.
Tagged: AI ChatGPT LLM prolog pyswip time travel
9. Prolog Strategy Map
Date Published: November 29, 2024
Date Added: September 14, 2025
Summary
This festive finale of my Prolog series weaves together enterprise strategy, logic, and human insight. I introduce strategy maps—graph-based visualizations that represent how objectives, beliefs, fears, and intents interconnect within an organization. These maps go beyond linear tree structures, capturing an enterprise’s “theory of mind.”
I show how Prolog breathes life into strategy maps by encoding them as modular logical structures that are transparent, testable, and auditable—far more robust than relying on LLMs alone. The essay emphasizes that these maps should be human-vetted and curated, preserving organizational nuance and frontline wisdom.
With Prolog as the logic core and LLMs as aid for drafting or enriching these maps, organizations can maintain control while embracing AI support. Humans remain central— intelligence emerges as a partnership, where AI brings reach and speed, but humans bring meaning, context, and intent.
In Chapter 9, the narrative culminated in strategy maps—Prolog encoded as living logic for organizational objectives and beliefs. Building on that, Chapter 10 asks the deeper question: once events occur, how do we anchor them in intent? Here, Prolog is no longer just representing strategy—it becomes the connective tissue between event and reasoning, converting logs into causal narratives.
10. Closer to Causation
Date Published: March 29, 2025
Date Added: September 14, 2025
Summary
In this spring break special, the spotlight turns to causation. I highlight that while event-based systems—from clicks to IoT streams—abundantly log what happened (“who, what, when”), they often fail to capture why it happened. Enter Prolog: by encoding the rules or logic that triggered an event, Prolog enables systems to attach reasoning directly to outcomes. Each event can carry with it not just metadata, but the exact version of the Prolog rule that caused it, plus the facts used. This practice ensures transparency, traceability, and auditability—offering a path beyond correlation toward true causation. The essay also introduces the concept of decoupled recognition and action, illustrating how reasoning happens in iterative loops, which Prolog is uniquely suited to represent and retain within event-driven architectures.
In this chapter, Prolog anchored causation, embedding logic into events to capture both actions and intent. Now, with “Thinking Reliably and Creatively”, that logic framework transitions into the realm of psychology and AI theory. Prolog evolves from the mechanics of cause to the architecture of thought: defining when speed suffices and when creativity must take the reins.
Tagged: AI complex event processing event streaming iot
11. Thinking Deterministically or Creatively
Date Published: July 4, 2025
Date Added: September 14, 2025
Summary
In this culminating chapter, I frame the conversation around neuro-symbolic AI through the lens of Daniel Kahneman’s System 1 and System 2 thinking—fast intuition versus slow deliberation. While the conventional mapping places neural networks as System 1 and symbolic logic (ex. Prolog) as System 2, I offer a compelling inversion: in enterprise BI, Prolog and Knowledge Graphs embody System 1—deterministic, traceable, and trusted for routine queries—while LLMs assume System 2—probabilistic, creative, and capable of tackling novel challenges. This symbiosis, I argue, mirrors human cognition: reflex when possible, reasoning when needed, all orchestrated in real-time to deliver intelligence that is both reliable and inventive.
Tagged: AI ChatGPT LLM neuro-symbolic ai symbolic ai
12. Trade-Off / Semantic Network – Prolog in the LLM Era – AI 3rd Anniversary Special
Date Published: November 8, 2025
Date Added: November 18, 2025
Summary
On the 3rd anniversary of the LLM era, this post revisits the forgotten roots of AI — Prolog, the Semantic Web/knowledge graph and cause-&-effect frameworks — and shows how they all converge in what I call the Trade-Off Semantic Network (TOSN). The TOSN pairs a semantic network (SN) — defining what exists — with a trade-off graph (TO) of metrics, configurations, and KPIs, and uses Prolog to capture the conditional logic that raw graphs can’t express. I share the origin story (tuning hundreds of SQL Server customers), proceed through a car-pedal-to-speed analogy to ground the model, and make the case that although today’s LLMs shine, they still need KGs and rule-engines like Prolog for transparency, control, and domain-specific reasoning. The post also touches on how world-model ideas (ex. Yann LeCun’s JEPA) fit into this stack, and argues that building structured, deterministic models (like TOSNs) is a skill that gives us back agency in the era of black-box AI.
Note: For the original graph formulation from that period, see US Patent No. 7,302,418 B2, “Trade-off/semantic networks,” issued Nov. 27, 2007.
Tagged: artificial intelligence Knowledge Graphs LLM nollm prolog
Closing for Part VII – Prolog in the LLM Era
This Prolog series has been a tour—from theory through practice, from logic and function to strategy and causation, and finally into cognitive architecture. Prolog has shown how deterministic reasoning remains vital, not as relic but as foundation. It enables clarity where LLMs offer creativity, history where LLMs propose futures, and reflex where LLMs explore. Together, they form a neuro-symbolic partnership: trusted systems for when precision matters and generative systems for when imagination is needed. Prolog is no longer a footnote—it is the backbone of strategic, auditable intelligence coexisting with the unpredictable potential of LLMs. In that hybrid lies the promise of AI that thinks, feels, and reasons with both speed and depth.
Part VIII – Pre-Aggregated OLAP
What I present in Enterprise Intelligence builds on many moving parts: knowledge graphs, process models, Prolog snippets, and AI agents. But all of these rest on a bedrock that is less glamorous yet absolutely essential: a solid BI foundation. One the key techniques that make this possible is pre-aggregated OLAP.
These essays revisit OLAP cubes, MDX, and aggregation managers not as relics of a bygone era, but as enablers of scale. When aggregations are chosen well and managed effectively, queries that would take minutes or hours can return in seconds. That performance boost does more than satisfy dashboards—it fuels the Insight Space Graph. With faster, cheaper exploration, ISG can chart more relationships, refresh more often, and open new pathways of analysis. In this sense, pre-aggregated OLAP is not just a tuning trick; it is the launch pad for Insight Space itself.
Related blogs on my Kyvos blog page:
1. The Role of OLAP Cubes in Enterprise Intelligence
Date Published: June 20, 2024
Date Added: September 14, 2025
Summary
This essay positions OLAP (Online Analytical Processing) cubes as foundational infrastructure for modern enterprise intelligence. I describe how OLAP enables rapid, multidimensional data analysis—across time, geography, product lines, and more—supporting sophisticated insights without compromising speed. This capability is especially powerful when paired with the Insight Space Graph (ISG) and Tuple Correlation Web (TCW) of the Enterprise Intelligence framework: OLAP cubes act as a performant cache that lets us prune large knowledge graphs while preserving agility and recall.
I also emphasize OLAP’s resilience under high concurrency—vital when multiple knowledge workers or AI agents query insights simultaneously. Pre-aggregations serve as resource-efficient caching, reducing computation and energy costs in ever-growing data landscapes. Finally, I explain how OLAP can bridge structured and unstructured data by integrating with modern platforms and LLMs, reinforcing that cubes are not relics but central pillars in scalable, responsive analytics today.
This essay explored how OLAP cubes serve as foundational infrastructure for enterprise intelligence, acting as performance-enhancing middleware between raw data and analytical insight. Now, we move deeper into how these cubes are queried. In The Ghost of MDX, the focus shifts from structure to language—showing how MDX, though often misunderstood, elegantly expresses multidimensional analytics in a way that SQL simply cannot.
Related blogs on my Kyvos blog page:
- Introducing Enterprise Intelligence
- The Role of OLAP Cube Concurrency Performance in the AI Era
- The Effect of Recent AI Developments on BI Data Volume
- The Need for OLAP on the Cloud
2. The Ghost of MDX
Date Published: November 9, 2021
Date Added: September 14, 2025
Summary
MDX (MultiDimensional eXpressions) often gets a bad rap, not because it’s conceptually complex, but because it operates in a different paradigm than SQL. It queries multidimensional cubes—structures built for analytics—where SQL works on flat tables. This post argues that, rather than dismissing it, we ought to appreciate how MDX and OLAP contract complex computations into formats analytics thrives on. MDX brings analytic queries closer to the semantic intentions of their designers and aligns with the matrix structures underpinning modern machine learning—regression, clustering, CNNs, and beyond. It’s less about teaching another language and more about recognizing that OLAP tools like MDX and Kyvos’s cloud-first SmartOLAP remain vital for fast, semantic analytics in a world increasingly overwhelmed by volume and velocity.
Having seen why MDX still matters in the modern context, the next step is to understand how it actually works. An MDX Primer unpacks the grammar and logic of the language, laying the groundwork for exploring how pre-aggregations can be designed and managed.
3. An MDX Primer
Date Published: December 2, 2021
Date Added: September 14, 2025
Summary
An MDX Primer breaks down the grammar and structure of MDX (MultiDimensional eXpressions), making clear how it differs from SQL. Whereas SQL works with flat tables and rows, MDX queries operate across multidimensional cubes, with axes, cellsets, tuples, and subcubes. The essay explains dimensions, hierarchies, attributes, and default members, showing how they interact to form a flexible query language for analytical systems. Beyond its mechanics, MDX is framed as an elegant way of reasoning across many dimensions—something that resonates with today’s high-dimensional spaces in machine learning, such as embeddings and optimization. Far from being a relic, MDX is presented as a precursor to modern multidimensional thinking.
Having laid out the grammar and concepts of MDX—so that the reader understands how multidimensional querying works—the next piece steps into optimization. We’ll now explore why pre-aggregations matter, and introduce the machinery needed to make OLAP perform at scale.
Tagged: Kyvos Insights MDX mdx tutorial OLAP cubes SSAS
4. The Ghost of OLAP Aggregations – Part 1 – Pre-Aggregations
Date Published: August 1, 2025
Date Added: September 14, 2025
Summary
This essay returns to OLAP cubes and explains the critical role of pre-aggregations: summarizing data in advance so that slice-and-dice queries run fast, even over massive datasets. It starts by acknowledging that many modern analytics engineers began after 2010, when in-memory warehouses, big data, and cloud platforms often made people believe cubes and aggregations were relics. Yet the core problems that cubes solved—volume, concurrency, cost—are no less real now.
The essay walks through how dimensional models underlie OLAP, how aggregations are persisted ahead of time (the “shelf-stocked pantry” analogy), and how different forms of aggregation (pre-aggregated, on-the-fly, virtualization) compare. It also calls out Kyvos as the current product that delivers these capabilities at scale, showing that pre-aggregations aren’t just historical artifacts—they’re foundational tools for performance in the present AI/BI landscape.
This essay laid out why pre-aggregations are essential, especially for high concurrency and query speed. From this foundation, OLAP Aggregation Manager picks up the work of maintaining and optimizing those aggregations—making sure they are relevant, efficient, and aligned with usage.
Tagged: AI database OLAP cubes pre-aggregated data sql sql-server technology
5. The Ghost of OLAP Aggregations – Part 2 – Aggregation Manager
Date Published: September 1, 2025
Date Added: September 14, 2025
Summary
In this final essay of Part VIII, the focus shifts from defining pre-aggregations to managing them. It presents the OLAP Aggregation Manager as the operational toolset that helps enterprises design, maintain, and evolve aggregation schemas. The essay explains how selecting which aggregations to build is trade-off heavy: storage vs. query speed, maintenance effort vs. performance payoff. The Aggregation Manager helps automate that decision process, tracking usage metrics, suggesting aggregations based on query patterns, and enabling pruning or reorganizing less-used ones. Combined with MDX querying and pre-aggregated cubes, the Aggregation Manager grounds the theoretical discussion in practical governance. It ensures systems stay performant, cost-efficient, and manageable as they scale.
Tagged: AI LLM olap systems thinking
Closing — Part VIII – Pre-Aggregated OLAP
This Part traced OLAP’s journey from cubes and MDX, through pre-aggregations, to the aggregation manager that governs them in practice. Each step highlights the same truth: speed is not a luxury, it is the multiplier of intelligence. A fast analytical substrate means richer ISG exploration, broader correlation webs, and more opportunities to push into higher-order reasoning.
As Principal Solution Architect at Kyvos, this is my one horse in the race. Pre-aggregated OLAP, delivered at cloud scale, is what makes the promise of Enterprise Intelligence attainable. Everything else in this book speaks to my passion for AI in its many forms—but it is this foundation, cubes and aggregations, that gives the Insight Space Graph its footing and the rest of the assemblage its chance to run.
Part IX – Horizontally Scalable Infrastructure
Horizontal scale, in this book, means adding new domains without rewiring the whole enterprise. As AI agents and IoT multiply the sources and granularity of data, the winner isn’t the cleverest single model but the infrastructure that can on-board a hundred more domains next quarter—with governance, lineage, and performance intact.
The pattern that keeps showing up is two-layer composability:
- Upstream (OLTP/operational): Domain-Driven Design (DDD) gives each domain a clear language and boundary. Event Storming → domain model → services.
- Downstream (analytics): Data Vault gives us a metadata-driven warehouse fabric—raw (Type-2) vault for fidelity, business vault for rules, and then marts/cubes—so new domains slot in as repeatable vault patterns instead of one-off projects.
Data Mesh then supplies the operating model: domain-owned data products on a self-serve platform. The Vault lives inside the platform as the warehouse layer that enforces coherence, while Mesh keeps teams decoupled and accountable. Add Snowflake as the elastic landing/processing plane and Kyvos as the acceleration/semantic layer, and you get something practical: thousands of BI consumers querying governed, pre-aggregated data at speed—no heroic SQL marathons.
This section traces that arc from design to run-time. We start with how DDD feeds a Vault so change is mostly metadata, not migrations (Entry 1). We then place the Vault inside a Mesh to manage the inevitable part-explosion with automation and platform guardrails (Entry 2). Finally, we connect the dots to Map Rock’s early idea—composing across independently built cubes via time and shared keys (Entry 3)—showing why a federated, loosely coupled approach beats monoliths once MDM and governance mature.
If the previous parts built the why for an Enterprise Knowledge Graph, this part is the how your organization keeps saying “yes” to new domains—without losing truth, traceability, or tempo.
Related blogs on my Kyvos blog page:
- Raw Data Vault to Star Schema, June 6, 2022
- Embracing Change with a Wide Breadth of Generalized Events, September 27, 2022
- Data Vaults and Knowledge Graphs, April 3, 2024
1. Data Vault Methodology paired with Domain Driven Design
Date Published: January 2, 2021
Date Added: September 14, 2025
Summary
Two sides of the same coin: DDD for OLTP design and a domain model that becomes the blueprint; Data Vault for OLAP with raw (type-2) vault → business vault → marts/cubes, all designed for metadata-driven automation (DevOps-friendly), with Snowflake/Kyvos as practical landing/serving layers. Includes a clear contrast with (and bridge to) Data Mesh.
We will now move from the backbone (DDD feeding a Vault) to the operating model—domain-owned data products on a self-serve platform, with the Vault as the warehouse layer that keeps governance and automation coherent.
2. Embedding a Data Vault in a Data Mesh – Part 1 of 5
Date Published: January 2, 2022
Date Added: September 14, 2025
Summary
Positions Data Vault as the warehouse layer inside Data Mesh: data products at the edge, vault in the platform, automation to manage the part-explosion, and Event Storming → Domain Model → Vault as the build path. Calls out the “Goldilocks zone” between schema-on-read lakes and rigid stars, and points to Kyvos for the consumer layer.
From architecture to composition technique—Map Rock shows how independently built products/cubes are stitched via time (and now MDM keys), a concrete capstone for composing at scale without reverting to a monolith.
3. Embedding a Data Vault in a Data Mesh – Part 2 of 5 – Event Storming to Domain Model
Date Published: September 20, 2022
Date Added: October 1, 2025
Summary
Shows how to go from sticky-note Event Storming to a first-pass Domain Model that both business and engineering can use—and that will feed a Data Vault implementation in the next part.
Using the fictional Gowganda Hospitality (hotels + restaurants across regions), we’ll frame the real problem. Each location needs autonomy, yet the enterprise still needs trustworthy, cross-domain analytics. This motivates a Data Mesh operating model (domain-owned data products with SLAs/SLOs) supported by a warehouse layer.
Core moves:
- Event Storming captures what really happens (past-tense, observable events).
- From those events you surface the things (entities) and boundaries (bounded contexts) that make up the domain.
- We’ll look at two Domain Model views—a conventional “boxes and lines” and a visual, non-programmer-friendly version with dashed contexts and event interfaces—to align business and tech.
- We’ll tee up the translation rule for Part 3: events become Links, things become Hubs, changing attributes become Satellites in the Data Vault.
Event Storming isn’t just a workshop—it’s a repeatable bridge from domain understanding to an executable model. That model feeds a Vault that can absorb change, and a Mesh that lets teams publish governed, high-quality data products without sliding back into a monolith.
4. Map Rock – 10th Anniversary and Some Data Mesh Talk
Date Published: November 20, 2021
Date Added: September 14, 2025
Summary
The “business-problem silos” era: many departmental cubes exist; Map Rock tried to correlate across cubes (date as the universal join) to form a web of relationships. The piece connects that idea to Data Mesh (domain data products + federation) and explains why a federated, loosely coupled approach wins over monolithic EDWs as MDM matured.
Part X – Planning
1.The Complex Game of Planning
Date Published: December 19, 2025
Date Added: December 19, 2025
Summary
Planning is not the act of choosing a goal or listing tasks. It is the harder problem of navigating a system with competing objectives, limited resources, probabilistic risks, and irreversible moves—where improving one outcome often degrades another. This blog treats planning as an intelligent, iterative process: a search through feasible sequences of change that reduce pressure without breaking the system.
I argue that most real-world planning—whether in enterprises, biological organisms, or future AI systems—can be understood in terms of events, KPIs, configurations, and pain thresholds rather than simple notions of success or failure. Using strategy maps, process mining, and event-driven models as a foundation, I frame planning as the management of trade-offs across time, where temporary discomfort is often necessary to escape worse long-term states.
The second half of the blog explores why this perspective matters for artificial intelligence. While large language models are effective tactical assistants, they lack the global context required for strategic planning. Genuine planning intelligence—human or artificial—requires the ability to reason about intermediate states, legality of moves, cumulative risk, and sequences of change. I introduce DōH, a conceptual planning game that treats strategy maps as a search space, illustrating how such reasoning might be made explicit and computable without copying the brain’s wiring.
This is an exploratory essay. It does not propose a finished system or claim neuroscientific authority. Instead, it offers a structured way to think about planning—grounded in enterprise systems, biology, and lived experience—as a capability that remains central to intelligence, and one that any serious attempt at AGI will eventually have to confront.
Part XI – System ⅈ
1. System ⅈ: The Default Mode Network of AGI
Date Published: January 9, 2026
Date Added: January 9, 2026
Summary
This essay argues that intelligence—human or artificial—does not begin with reasoning, planning, or language. It begins with continuous background exploration over integrated, time-structured experience. I call this System ⅈ.
System ⅈ is not a thinking engine. It does not optimize, decide, or explain. It wanders. It notices coincidences, gaps, inflection points, and recurring patterns across time, domains, and context. In humans, this role is visible in phenomena like the Default Mode Network, curiosity, incubation, and insight after rest. In enterprises, it already exists in practice through Business Intelligence: analysts define problems, explore data, discover patterns, and gradually externalize what matters into dashboards, metrics, models, and processes.
The core claim is that BI systems (the data, software, and human BI Analysts)—when integrated, time-aware, and trusted—are already a substrate for intelligence, not merely reporting tools. Structures like the Insight Space Graph (episodic memory), Tuple Correlation Web (associative memory), and Time Molecules (process memory) form a patterned field that System ⅈ can explore continuously. Vector embeddings, process discovery, genetic search, deep symbolic reasoning (e.g., Prolog), and long-running model experimentation belong here—not as fast responders, but as background processes that surface candidates for attention.
Reasoning (System 2) and fast response (System 1) come later. They assimilate what System ⅈ discovers into rules, models, and habits. Intelligence emerges not from finding optimal answers, but from discovering useful constraints, good-enough local peaks, and stable patterns in an ever-changing landscape.
The broader point is not that enterprises are “becoming AGI,” nor that LLMs are intelligence. It is that we have been building externalized cognition for decades, and that real progress comes from recognizing, strengthening, and connecting these layers—rather than expecting intelligence to arrive fully formed as a single model or agent.
2. Explorer SubGraph
Date Published: February 2, 2026
Date Added: February 2, 2026
Summary
This blog continues from the System ⅈ perspective, where intelligence begins as a web of correlations and conditional probabilities captured in the Tuple Correlation Web (TCW). Within that framework, reasoning proceeds by traversing chains of strong statistical relationships. But not all meaningful structure in a system appears as strong correlation. Some relationships are indirect, asymmetric, or economically small, and others only become visible when the system is examined at a different level of granularity.
The Explorer Subgraph is introduced to address this boundary. It is not an ontology and not a replacement for statistical grounding, but a hypothesis overlay that records how things participate in other things—through roles, components, materials, processes, and conditions. When TCW paths narrow or stall, the Explorer Subgraph provides plausible adjacencies that allow the system to descend, decompose, and re-enter correlation space elsewhere.
The blog frames moderate probabilities as navigational signals rather than weak conclusions, showing how weak or indirect signals can justify further exploration when decomposed through roles. It also reframes confounders as disclosures rather than errors: moments where underlying structure becomes visible because surface correlations are no longer sufficient. Emergent properties are treated as waypoints—useful signals that invite analysis to move downward toward the parts that sustain them, especially when those properties collapse under change.
Taken together, the TCW and the Explorer Subgraph form a continuous reasoning system. Correlations and conditional probabilities establish what is statistically strong; role-based exploration proposes what is adjacent; and breakdowns and confounders reveal what must be true for observed behavior to exist at all. The result is a way of navigating complex systems that respects how they actually reveal themselves—incrementally, unevenly, and often only when implicit structure can no longer remain hidden.
3. Chains of Unstable Correlations
Date Published: February 13, 2026
Date Added: February 13, 2026
Summary
This chapter explores how nonlinear relationships—especially hockey-stick and threshold curves—reveal hidden fragility within enterprise systems. While many correlations appear stable and linear on the surface, this blog focuses on the regimes where small upstream changes trigger outsized downstream consequences. Through scatter plots, segmentation analysis, and Simpson’s-paradox-style aggregation effects, it demonstrates how correlated tuples can form cascading risk chains within the Tuple Correlation Web (TCW). The discussion extends into detection strategies, regime identification, and how these nonlinear signals can be operationalized within the Assemblage architecture—surfacing early warnings to System 1 and System 2 reasoning layers. Ultimately, the piece frames unstable correlations not as statistical curiosities, but as structural intelligence signals essential for preserving organizational awareness and decision agency in increasingly automated environments.
4. The Insight Function Array
Date Published: March 30, 2026
Date Added: March 30, 2026
Summary
Part XII – The Third Act
The final act of The Assemblage of Artificial Intelligence focuses on how intelligence produces durable structures that can be reused, refined, and transmitted. The earlier parts of the book assembled the pieces—knowledge graphs, BI foundations, machine learning, Markov models, Prolog reasoning, and large language models. Part XII explains how these pieces work together to generate the artifacts of intelligence.
At the heart of this act is a simple observation: intelligence operates over processes unfolding through time. In business systems, we observe processes as event streams—customer journeys, production workflows, supply chains. In analytics, these become statistical models of transitions, such as Markov structures derived from observed sequences. In human cognition, those same processes are remembered and communicated as stories. A story is simply a process enriched with context, causation, and meaning.
These representations form a progression:
Events → Processes → Stories → Plans
- Events are the raw observations recorded in systems and data streams.
- Processes are the statistical skeletons extracted from many events—patterns of what tends to follow what.
- Stories are the human representation of processes, attaching intent, causation, and meaning to sequences of events.
- Plans are future-directed stories: deliberate attempts to shape processes toward desired outcomes.
This progression explains why the products of deliberate reasoning—what cognitive science calls System 2—are so important. The lasting contribution of System 2 is not momentary thoughts but durable artifacts: procedures, designs, narratives, strategies, models, and institutions. These artifacts accumulate across generations to form civilization’s reusable knowledge library.
Part XII shows how an artificial intelligence architecture can replicate this cycle:
- Observe processes through event streams and enterprise data.
- Learn process structure using statistical models such as Markov chains and machine learning.
- Represent meaning and relationships using knowledge graphs and symbolic reasoning.
- Generate narratives and plans through higher-level reasoning and language models.
- Harden successful outcomes into reusable structures that become part of System 1.
In this architecture, intelligence is not the property of a single model. It emerges from an assemblage of interacting subsystems that convert experience into reusable knowledge. Machine learning captures statistical regularities. Knowledge graphs preserve relationships and context. Logic systems encode constraints and causation. Language models help synthesize narratives and analogies. Together, they form a cycle in which processes are learned, interpreted, and deliberately reshaped.
The “third act” therefore moves beyond assembling components to revealing the deeper pattern beneath them. Intelligence—human or artificial—is the ability to recognize processes, represent them as stories, and manipulate them as plans.
Civilization itself can be understood as the accumulated library of these products of intelligence.
1. The Products of System 2
Date Published: March 4, 2026
Date Added: March 4, 2026
Summary
This post is a sweeping, analogy-rich exploration of deliberate reasoning—both in human cognition and emerging AGI architectures—that reframes creativity, intelligence, and originality as evolutionary-cultural processes rather than flashes of pure invention.
I draw on dual-process theory of Danieal Kahneman to contrast System 1 (fast, reflexive, pattern-driven: OODA loops in action, trained ML models, probabilistic “time molecules” from aggregated Markov chains) with System 2 (slow, effortful, analogy-mediated reasoning that intervenes when routine recognition fails). The blog’s central thesis is that System 2’s true legacy is not transient thoughts but durable, transmissible artifacts—the “products” that accumulate as civilization’s reusable knowledge library, akin to biological evolution’s library of surviving forms or cultural memes.
These artifacts include:
- Stories — causal sequences encoding “how” and “why” (the transactional core of human-level intelligence, enabling abductive leaps)
- Plans — bridges from undesired to desired states
- Procedures, recipes, instructions — serialized transformations
- Models, designs, assessments — compressed abstractions and evaluations
Progress emerges from a flywheel: notice patterns → map via analogy → harden through testing/failure → transmit/plow back. True breakthroughs are rare “happy accidents”; most arise from remixing distant analogies (e.g., shark–tiger predator archetypes, coastal ecology cascades turned into Prolog rules with Wikidata IRIs, plumber logs clustered into Markov diagnosis–treatment flows, Manhattan cocktail families encoded logically, bathroom renovation dependency hierarchies).Asahara illustrates hardening vividly: visual correlations → narrative → executable Prolog → ontological IRIs → shareable graph structures. LLMs shine as supreme analogy engines, surfing humanity’s vast pattern sea, yet they remain dependent on pre-hardened structure. The post-LLM future lies in hybrid neuro-symbolic stacks:
- LLMs for fuzzy generation and serialization
- Prolog (or evolutions like Soft Coded Logic with MetaFacts/MetaRules) for deterministic, backtracking, recursive execution
- Enterprise Knowledge Graphs (EKGs) for ontological scaffolding
- Vector memory for semantic retrieval
- IRIs as universal glue
The main point of this blog is that intelligence mirrors nature more than heroic genius. The Products of the System 2 of our brains are to human culture as every feature of every creature is to evolution’s library of living solutions. Therefore, scalable AGI should replicate this cycle at machine speed—generate → harden → reuse—rather than chase disembodied reasoning.
2. Time Molecules, AI Agents, and Context Engineering
Date Published: March 10, 2026
Date Added: March 10, 2026
Summary
Copyright Notice
© 2013–2026 Eugene Asahara. All rights reserved.
This website and its contents, including but not limited to The Assemblage of Intelligence (book blog) and all individual blog posts comprising it, are protected under United States and international copyright law. Each blog post is a copyrighted work in its own right, and the collection of posts arranged as The Assemblage of Intelligence constitutes a collective work.
Excerpts and quotations may be used for purposes such as education, scholarship, or review, provided that proper citation and attribution are given to the author. Suggested Citation (APA style):
Asahara, E. (2025). The Assemblage of Intelligence [Blog series]. Eugene Asahara. https://eugeneasahara.com
No part of this work may otherwise be reproduced, distributed, or transmitted in any form or by any means, including photocopying, recording, or other electronic or mechanical methods, without the prior written permission of the author.
Requests for permission should be directed to me (the author, Eugene Asahara) at eugene@softcodedlogic.com
Appendix A
Date Added: November 10, 2025
Last Updated: November 10, 2025
Throughout my posts/essays/blogs up to November 10, 2025, I’ve been referring to systems like ChatGPT, Grok, and Gemini simply as LLMs. At the level most people interact with them, that shorthand makes sense.
In reality, today’s “LLMs” are much more than a single model. They’re ensembles—architectures built from three major components:
- The core language model, which handles reasoning, pattern recognition, and generation.
- A retrieval and tool layer, which brings in external data and specialized functions.
- An orchestration layer, which manages context, routing, and policy across all the experts involved.
The LLM may be the flagship—like an aircraft carrier in a carrier group—but it’s surrounded by a coordinated fleet of supporting systems. For convenience, and because there’s no broadly accepted term for this full ensemble yet, for now (November 10, 2025), I’ll keep using LLM in this post.
I’ll also avoid calling them (ChatGPT, Grok, etc.) simply AI, since that term is too broad for my purposes here. In this context, as I describe in The Assemblage of AI, AI includes other components such as knowledge graphs, Prolog reasoning, complex event processing (CEP), and non–neural network machine learning—all of which contribute to enterprise-scale intelligence beyond the language model itself.
Some people have started using the term Cognitive Mesh to describe this kind of architecture—a distributed network of reasoning components working together. In my framework, the LLM is one node in that mesh, joined by knowledge graphs, Prolog inference, complex event processing, and other analytical models. Each contributes a different mode of cognition: symbolic, temporal, statistical, or procedural.
When a generally accepted term does emerge, I’ll just start using it.
I’ve been thinking of “LLM Constellations” or just “Constellations”. But the former emphasizing that LLMs are at the center of the group—as it is for ChatGPT, Grok, Gemini, Claude, etc. as of Nov 10, 2025). Right now, I see LLMs as holding the dominant central position in the same way that the neocortex is the dominant centerpiece of our human sentience.
Update (March 3, 2026)
I’d like to clarify some terminology used in this post. When I refer to “OLAP cubes”, I’m specifically highlighting the multidimensional data structure optimized for analytical queries—distinct from relational databases traditionally geared toward OLTP (Online Transaction Processing) patterns. Kyvos originally built on this OLAP foundation for high-performance analytics at scale (ca. 2015). However, the Kyvos platform has since evolved into a comprehensive semantic layer that delivers a unified, consistent business view across disparate data sources—ensuring “one view, one meaning” for metrics, dimensions, and relationships enterprise-wide. This semantic model retains the core acceleration structures for query speed and efficiency—even more valid today as multiple factors expand the need for trusted data—while expanding to support modern AI-driven insights, data mesh, and enterprise intelligence frameworks. OLAP described how it accelerated analytics. Semantic model describes what it represents. For the latest on Kyvos, check their official resources at kyvosinsights.com.
