This post maps the ideas in the recent paper Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention (Munkhdalai, T., Faruqui, M., & Gopal, S. 2024) to concepts from my book, Enterprise Intelligence, including the Tuple Correlation Web (TCW), Insight Space Graph (ISG), and cubespace as a semantic layer. In business intelligence (BI) and artificial intelligence (AI), the topic of context is a fundamental challenge. Whether navigating vast data warehouses or processing continuous streams of user interactions, the ability to retain and utilize salient points—the high-level gist of any experience or observation—is the one of the cornerstones of meaningful analysis.
Thanks to TheAIGrid for the video, OpenAI and Microsoft Just Made a Game changing AI Breakthrough For 2025, that brought the paper to my attention. It provides a very nice high-level view of the paper. It’s a good idea to watch the video first, but here is a little summary:
The video explores advancements in AI expected by 2025, focusing on the introduction of infinite memory and infinite context windows. Infinite memory enables AI systems to retain and recall information across extended periods, allowing for the development of long-term relationships, continuous tracking of user needs, and reasoning over vast datasets like codebases or libraries.
A couple of notes before continuing:
- In the context of this blog, reading the paper, Leaving no Context Behind, isn’t necessary. However, first watching the TheAIGrid video for the AI side of infinite context and reading the TL;DR of Enterprise Intelligence for the BI side will be very helpful.
- The talk of “infinite memory” in relation to AI is “[near] future talk” at the time of writing.
Mapping the concepts of infinite memory to what I describe in Enterprise Intelligence isn’t a perfect analogy below the 50,000 foot level. The main point is to store, for future reference, compact memories of what we talked about and/or what happened long ago. Imagine if we couldn’t remember things from the past—there would be no such thing as learning.
On the other hand, imagine if our poor brain had to remember every single photon our retina picked up, every sound wave our ears detected, and every molecule our nose detected. The trick is we need to store the memories in a compact and easily recallable manner. In fact, all of our memories are compact and readily accessible abstractions of that raw data.
Infini-attention: Storing Infinite Context
As we relentlessly push the performance of AI, one of the significant challenges is managing the need for larger context windows—like attempting to process all the books in a library while remembering every word. Infini-attention addresses this by utilizing compressive memory—a mechanism in AI models that condenses less relevant past information into summarized representations while preserving critical context. This allows for efficient processing of lengthy inputs. Rather than retaining every detail, it prioritizes and stores only the most essential points.
This approach combines two methods: focusing on the nearby text and keeping a condensed memory of the longer-term context. The result? AI can process texts with millions of words without getting overwhelmed or running out of capacity. It’s a big step forward for tasks like summarizing books or analyzing long documents.
Infini-attention is all about scaling AI to manage “infinite” context while keeping things efficient and fast—a game changer for long-context tasks.
When AI (I’m mostly talking about LLMs) processes information, it generates keys (what the data represents) and values (the actual content). This consumes compute and is pretty much just thrown away. Infini-attention saves these in a compact format so they can be retrieved later when needed. This memory acts like a searchable archive, where AI can pull up relevant past knowledge to combine with what it’s working on right now. It’s a blend of short-term focus and long-term context.
Why does this matter? Compact, searchable memory means AI can handle more complex tasks without bogging down. It doesn’t forget, it just gets smarter about what it remembers. This idea of conserving and reusing context reminds me a lot of the TCW and ISG in I lay out in Enterprise Intelligence—they also make past insights easy to access and integrate, saving time and effort while keeping the focus on what’s important.
The Insight Space of the Semantic Layer
In Enterprise Intelligence, I describe the ISG and TCW as structures designed to conserve and organize context within a BI environment. Both the ISG and the TCW serve as searchable context in the realm of Enterprise Intelligence. Their power lies in their ability to cache insights and correlations derived from BI queries, ensuring that these findings are preserved and easily accessible for future use.
Figure 1 shows the progression of memories within an enterprise. It begins with what goes on in the physical world of customer, their problems, enterprise operations, partner relationships, etc. The seemingly “relevant” data is captured in our databases into a data space. Those databases are formatted into a semantic layer (cube space), which is a friendlier, curated view of the data space.
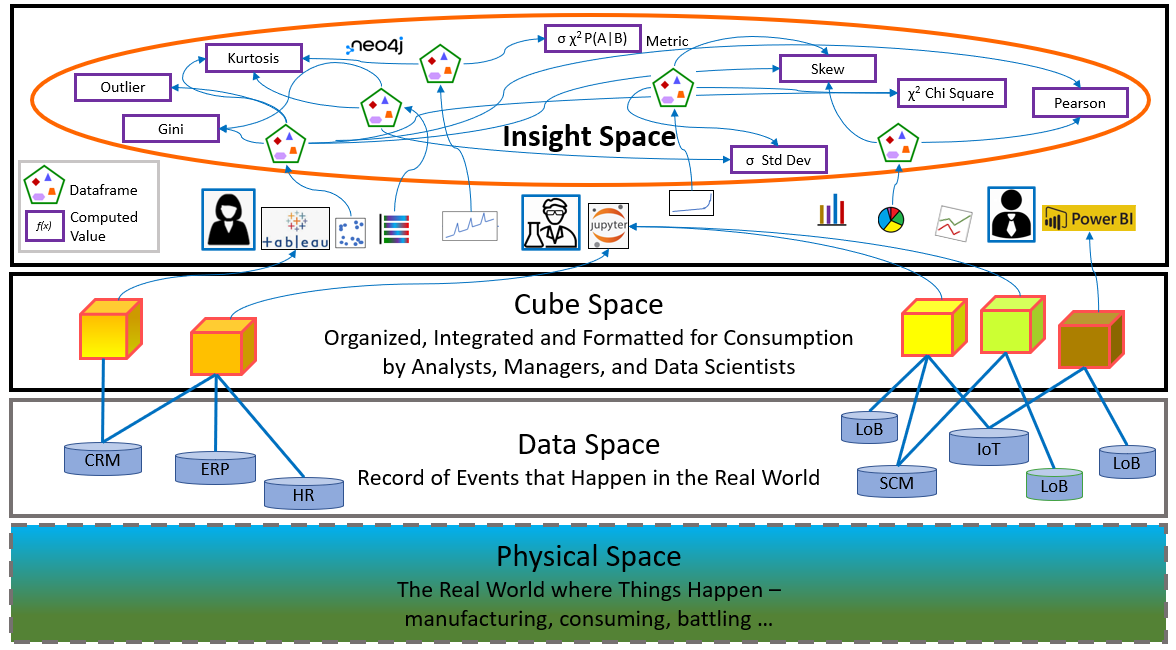
Insight Space is a combination of human intelligence and data. Knowledge workers, analysts, and managers, query the semantic layer for data in the context of their tasks. Humans fold into Insight Space the:
- Problem Dimensions, the tasks they are addressing.
- Thought Dimensions: The unique ways sentient humans come up with to resolve problems.
- The Facet Dimensions: The different points of view of how data is visualized.
Every insight tuple within the Insight Space comes to attention through unique paths of inquiry that might never lead to that same insight tuple. These insights can be noted without needing to figure out how we originally came up with them.
Why Searchable Context Matters
If the ISG and TCW didn’t cache these insights, analysts or an AI system would need to re-query the underlying BI databases repeatedly. They probably won’t really remember how they got to some insight either. This not only increases computational costs but also delays decision-making by needing to re-discover the insights. By caching the insights and correlations, both structures enable rapid retrieval and exploration of historical insights, transforming BI from a reactive process to a proactive, discovery-driven framework.
- ISG: Caches the salient points from visualizations, descriptive analytics, and BI activity. These insights can then be searched and reused across different contexts without having to regenerate them.
- TCW: Captures the correlations and relationships between multidimensional data, making these connections readily available for exploration. Analysts can query patterns and trends dynamically instead of re-running complex analyses.
Figure 2 illustrates how Enterprise Knowledge Graph (EKG) structures, the ISG and TCW, fit into a broader knowledge ecosystem, showing their role in caching and organizing insights for rapid access.
- ISG: Positioned in the Business Intelligence section, the ISG represents cached insights from visualizations and descriptive analytics. These stored insights are part of a broader, searchable graph that analysts can quickly reference. Without this layer, analysts would need to regenerate these insights from raw data repeatedly, wasting time and computational resources.
- TCW: Also in the Business Intelligence section, the TCW focuses on capturing and storing relationships and correlations between data points across dimensions like time and geography. This structure ensures that patterns and trends are readily available for exploration without needing to re-run the complex analyses that generated them.

The Data Catalog in the center bridges the gap between the raw data in databases and the semantic representations in the ISG and TCW. The catalog organizes and integrates data, making it ready for the ISG and TCW to cache and leverage insights.
In this system:
- The Knowledge Graph on the left provides a conceptual framework for subject matter experts to structure relationships and ontologies, feeding into the BI tools.
- The ISG and TCW ensure that cached insights and correlations are accessible, proactive tools for exploration and decision-making, preventing costly and inefficient re-computation.
This visual underscores how caching insights in the ISG and TCW transforms BI workflows from reactive query processing to a proactive, insight-driven framework.
Parallels to Infini-attention
This concept of caching searchable context mirrors the mechanism in Infini-attention:
- Caching for Searchability:
- In Infini-attention, key-value pairs are cached in compressive memory. This allows the model to search for and retrieve relevant information dynamically, instead of recomputing context from scratch.
- Similarly, the ISG and TCW cache insights and correlations, making them searchable and reusable for future queries.
- Avoiding Re-querying:
- Without cached memory in Infini-attention, the model would need to reprocess previous sequences to retrieve context, leading to inefficiency.
- Without the ISG/TCW, BI analysts would need to re-run queries and recompute correlations every time they needed an insight, making the process slower and more resource-intensive.
- Searchable Knowledge as a Foundation:
- Just as Infini-attention enables the model to dynamically query past knowledge, the ISG and TCW allow analysts to search and build upon cached insights, ensuring continuity and efficiency in decision-making.
A Unified Vision of Cached Context
By caching salient points and relationships, both Infini-attention and the ISG/TCW ensure that knowledge remains searchable, reusable, and scalable. This eliminates the need for constant re-computation, making insights more actionable and reducing the time between query and decision.
The ISG and TCW serve as the BI counterpart to Infini-attention’s compressive memory, conserving insights and correlations as searchable context—a principle that underscores the growing importance of cached intelligence in both AI and BI.
A Shared Philosophy: Conservation of Knowledge
Infini-attention and the EKG share a core philosophy: conserve knowledge, make it actionable, and dynamically integrate it with current data. While Infini-attention focuses on the massively multi-dimensionality of language and long-term memory, the EKG applies this principle to the long-term memory of an enterprise, ensuring that every query and insight feeds into a growing, interconnected system of organizational intelligence.
Notes:
- Enterprise Intelligence: Integrating BI, Data Mesh, Knowledge Graphs and AI, is my long-version book description.
- Enterprise Intelligence is available at Technics Publications and Amazon. If you purchase the book from the Technics Publications site, use the coupon code TP25 for a 25% discount off most items (as of July 10, 2024).
- The Enterprise Intelligence category of this blog site is a list of my blogs related to the book.
- Videos and articles that seem to support my confirmation bias towards what I’ve presented in Enterprise Intelligence.
