

I’m excited to announce that I will be speaking at the Data Modeling Zone 2025 (DMZ) in Phoenix. It will be happening from Tuesday, March 4, 2025 through Thursday, March 6, 2025.
I have two sessions lined up:
- Enterprise Intelligence Overview (Tuesday, March 4, 2025 9:00am-12:30pm): A three-hour live-version of my book Enterprise Intelligence. This session delves into the essence of my book, which explores how to leverage business intelligence, semantic layers, knowledge graphs, data mesh, AI, and advanced computational methods to create actionable insights at scale.
- Knowledge Graph Structures Beyond Ontologies and Taxonomies (Wednesday, March 5, 2024 10:15am-11:15am): This one-hour session covers knowledge structures that are rarely considered part of knowledge graphs (KG), going beyond typical business ontologies like a product taxonomy (e.g., categorizing products by their type, such as electronics → smartphones → Android phones). Instead, I’ll explore less conventional but highly valuable structures, including strategy maps, trophic cascades, Hidden Markov Models, and Non-Deterministic Finite Automata (NFA).
I’ve written much supplemental material about Enterprise Intelligence in a blog series. I’ve also written much about the structures mentioned for my 2nd session. For example, I’ve written many blogs on strategy maps:
- Bridging Predictive Analytics and Performance Management
- Revisiting Strategy Maps: Bridging Graph Technology, Machine Learning and AI
- KPI Status Relationship Map Revisited with LLMs
- The Effect Correlation Score for KPIs
- KPI Cause and Effect Visio Graph
- Prolog Strategy Map – Prolog in the LLM Era – Holiday Season Special
Why might those structures belong in a knowledge graph? The short answer is simple: they represent knowledge, and it is a “knowledge” graph. Each of these structures provides a unique perspective—a view of a problem or system. For instance, strategy maps represent goals and the relationships between them, while trophic cascades model how changes in one part of an ecosystem ripple through others. Adding these perspectives to knowledge graphs enriches their ability to represent complex systems.
So here is a sample of one of those structures we’ll discuss in the knowledge graph session.
Non-Deterministic Finite Automata (NFA)
For a little sample of my knowledge structure session, let’s talk about NFA. Like ontologies, NFAs are built on a framework of triples. However, while ontologies use the subject-verb-object format (e.g., “loan → has status → approved”), NFAs use the state-event-state format, focusing on events and state transitions.
For example:
- State: “Reviewing Loan”
- Event: “Loan Reviewed”
- Next State: “Awaiting Approval”
This dynamic nature makes NFAs ideal for modeling processes where events cause transitions between states, such as in workflows, business processes, or even biological pathways.
One significant value of embedding NFAs into a KG lies in their use within a Retrieval-Augmented Generation (RAG) process. A KG allows RAG systems to reference and traverse the relationships and processes modeled by NFAs, providing dynamic and context-aware knowledge retrieval. This is particularly valuable in domains like healthcare or finance, where processes and decisions are event-driven.
In a completely different use case, scalable NFA processors, such as the now-defunct Micron Automata Processor (AP), offer another way to process NFAs at scale. These systems focus on raw parallelism, where thousands of NFAs can be evaluated simultaneously for each symbol, enabling real-time pattern recognition and sequence validation.
Theory of Computation: Where Does NFA Fit In?
NFAs are near the bottom of the computation stack—that seemingly meaningless course you took as a requirement for your CS degree. At the top is the Universal Turing Machine (UTM), which forms the foundation for modern CPUs and RAM. Each core of a modern multi-core processor is effectively a UTM, capable of executing general-purpose computations through programming instructions.
A few steps below UTMs, we sort of have programming languages, which are not formally part of the computation stack but draw heavily on its concepts. Programming languages achieve their computational power from being Turing Complete, meaning they can theoretically compute anything a UTM can. However, their syntax—the structure of their statements and expressions—is derived from context-free grammars (CFGs). CFGs form an essential foundation for parsing and interpreting programming languages, describing constructs like if-else, loops, and nested function calls. Pushdown automata (an extension of finite automata with a stack) are used to parse these CFG-defined languages.
Slightly lower in the stack are Regular Expressions (RegEx), which describe regular languages that can be recognized by finite automata. RegEx should be familiar to programmers. RegEx is in a sweet spot of simplicity and usefulness—powerful enough to handle most pattern-matching tasks yet relatively straightforward to implement. For example, the RegEx pattern \bcat\b matches the word “cat” (bounded by word boundaries), making it ideal for quick text searches. However, as most programmers know, RegEx can quickly become unwieldy when handling more complex patterns or hierarchical structures.
At the very bottom of the computation stack are Finite State Automata (FSA), the simplest computational model. FSAs form the foundation of Regular Expressions (RegEx) and are limited to recognizing regular languages. They are incapable of handling nested or hierarchical structures, such as balanced parentheses, because they lack memory beyond their current state.
Moving slightly higher in complexity, we have Non-Deterministic Finite Automata (NFA), a subtype of FSA. While NFAs are more versatile than deterministic FSAs (allowing multiple possible transitions for a given input), they remain relatively simple models in comparison to more powerful computational frameworks like Turing Machines.
Despite their simplicity, NFAs have a real strength in parallelism. They can process sequences simultaneously across multiple paths, much like how multi-core CPUs and GPUs work. This makes them ideal for tasks like recognizing patterns from thousands of rules in real time, validating workflows, or tracking state transitions in processes.
NFAs can theoretically (that’s pushing it) perform everything a Universal Turing Machine (UTM) can do, but in practice, their lack of memory and inability to handle nested data structures make them grossly unsuitable for general-purpose computation. Instead, their power lies in their ability to efficiently model and validate event sequences (simple computations), especially when embedded into larger systems like Knowledge Graphs.
This hierarchy demonstrates how different computational models—from finite automata to context-free grammars and Turing Machines—contribute to the design and power of programming languages, while also showing the elegance and utility of simpler models like NFAs and RegEx in handling specific tasks.
Recognizing Sequences
NFAs excel at recognizing valid sequences, whether they are sequences of symbols (like text patterns) or events (like workflow steps). They are not about predicting the next event—that’s the role of Markov Models, which assign probabilities to the transitions between events.
In contrast:
- Markov Models: Focus on predicting what happens next based on probabilities.
- NFAs: Validate whether a sequence adheres to a defined structure or path.
For instance:
- A Markov Model might predict that after “Loan Reviewed,” there is an 80% chance of “Loan Approved.”
- An NFA would recognize whether the sequence “Loan Reviewed → Loan Approved” is valid.
Figure 1 is a fun and simple NFA to recognize a phonetically valid spelling of Eugene. Can you see all the ways? Eugene, Ugeen, Ewejeane …
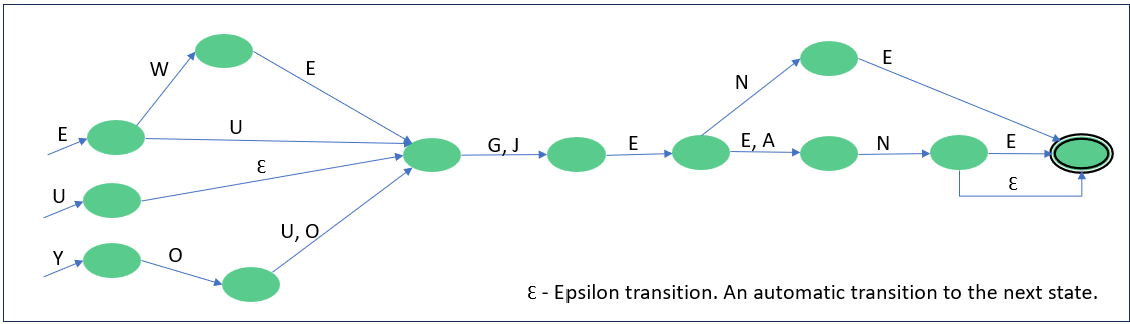
Figure 2 is a more business example of an NFA—the various paths a restaurant guest could take.
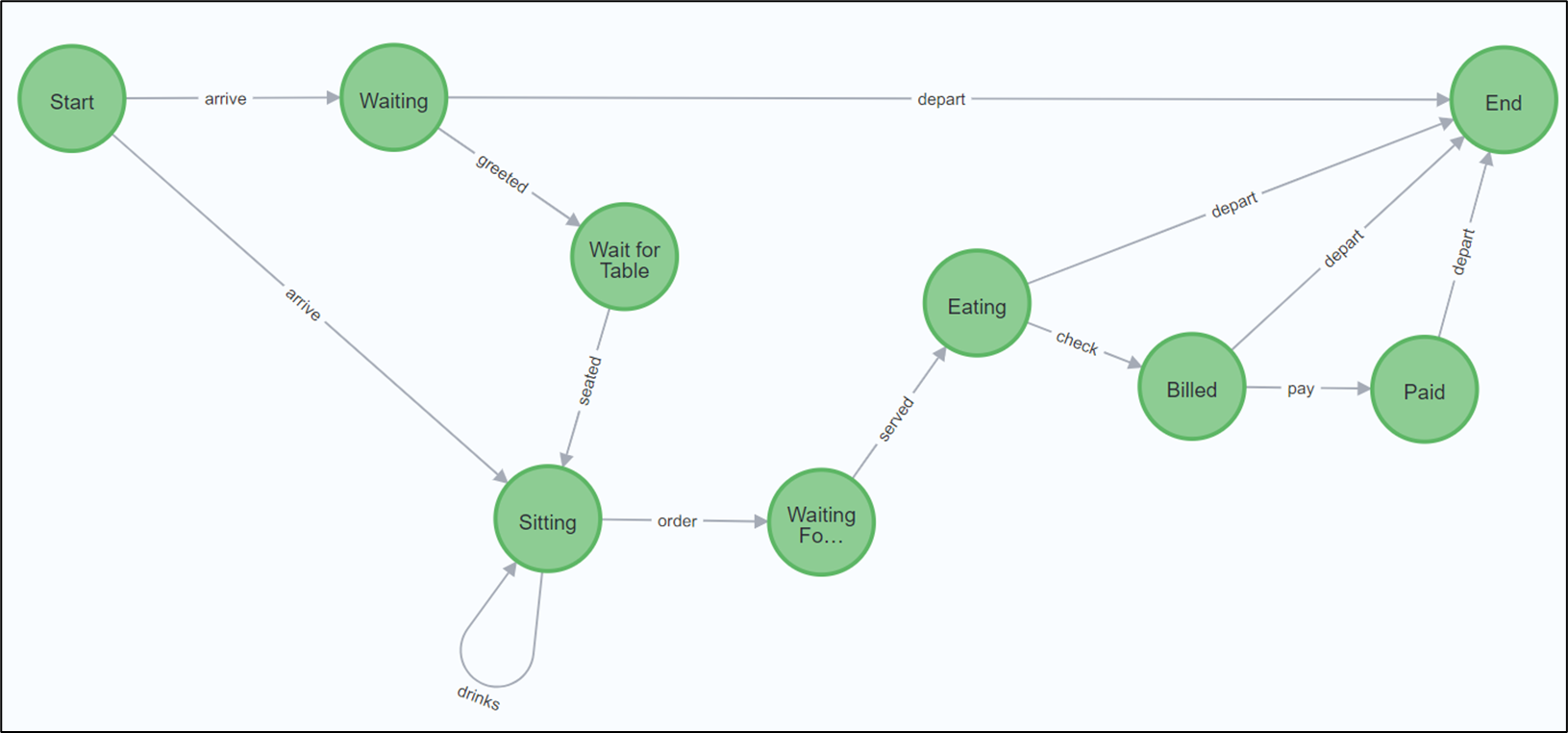
Notice valid paths include eating and just leaving … hahaha.
Figure 3a is an example of an NFA used to predict a risk for diabetes, a chronic illness, before it happens.
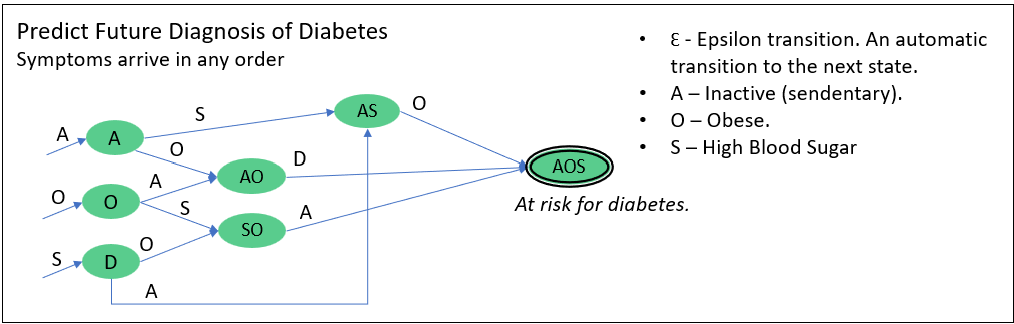
Figure 3b looks similar to Figure 3a, but predicts risk for cardiovascular disease.
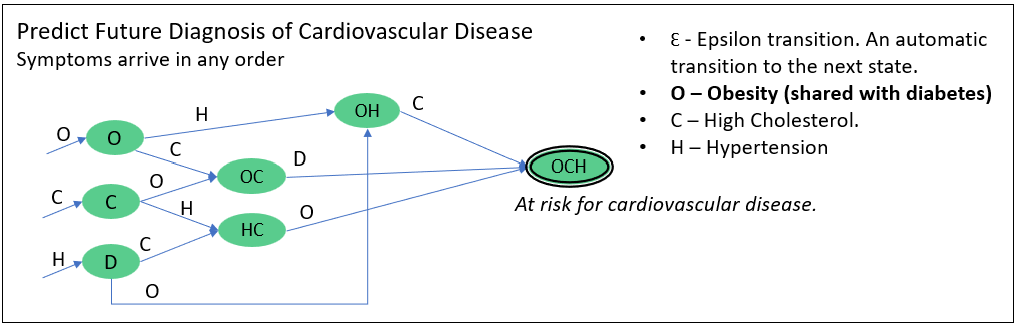
Notice that predicting risk for diabetes and cardiovascular disease share the common characteristic of obesity. Later, we’ll see that these two NFA (along with thousands of other NFA) could be processed in parallel. Meaning, if a patient had the characteristics, {A, O, S, C), each symbol is processed by both in parallel. In this case, we’d see the patient is at risk for diabetes, but not quite for cardiovascular disease.
Of course, there are dozens of ways we know of (and yet to be discovered) for measuring the risk for chronic diseases. Some rules can be merged into a compound NFA while others can be in separate and simple NFAs.
Example: NFA Embedded in a Knowledge Graph
Traditional ontologies in KGs primarily focus on static relationships such as “is a”, “a kind of”, or “has a”. These relationships describe hierarchical knowledge (e.g., “Dog is a Mammal”) or compositional knowledge (e.g., “Car has a Engine”). They are well-suited for organizing and representing concepts, attributes, and metadata in structured ways.
However, embedding NFAs into a KG introduces a new dimension by modeling processes and event-driven behaviors rather than static relationships. NFAs focus on states and the events that trigger transitions between them. For example, an NFA might describe how a loan application transitions from “Reviewing Loan” to “Awaiting Approval” after a “Loan Reviewed” event, which is fundamentally different from static relationships like “Loan is a financial instrument.”
This difference highlights why NFAs are not considered typical ontologies. While ontologies are concerned with describing what is or what has, NFAs describe what happens. They bring temporal and procedural knowledge to the KG, enabling it to capture workflows, event sequences, and state transitions.
Traditional KGs rarely include this type of process-based knowledge, focusing instead on the hierarchical and compositional structure of concepts. However, KGs are inherently flexible and can be expanded to include NFAs. By treating states as nodes and events as edges, NFAs can be fully embedded in a KG, providing dynamic, event-driven relationships alongside the traditional static ones.
This hybrid approach creates a comprehensive KG that combines static ontological knowledge with dynamic behavioral knowledge. For example, a KG could include both the ICD-10 classification of diseases (“COPD is a Respiratory Disease”) and the procedural pathways leading to a COPD diagnosis (e.g., smoking and mucus production triggering transitions in an NFA). This integration is particularly powerful in domains like healthcare, where both static classifications and dynamic patient journeys are critical, or in e-commerce, where customer behavior can be modeled as event-driven pathways leading to a purchase.
Embedding NFAs into a KG represents a broader and more innovative approach to knowledge representation. While it deviates from the traditional “is a” or “has a” ontology, it aligns with the goal of KGs to represent real-world systems comprehensively. By including NFAs, you’re expanding the KG’s scope to capture not just what entities are and what they have, but how they behave and change over time. This hybrid structure enables richer insights and supports applications that demand both static and dynamic knowledge, such as real-time monitoring, anomaly detection, and process optimization.
Figure 4 is a graphical sample of two NFA linked to a sample of an ontology. This example is loosely based on a system I once participated in developing towards preventive healthcare.
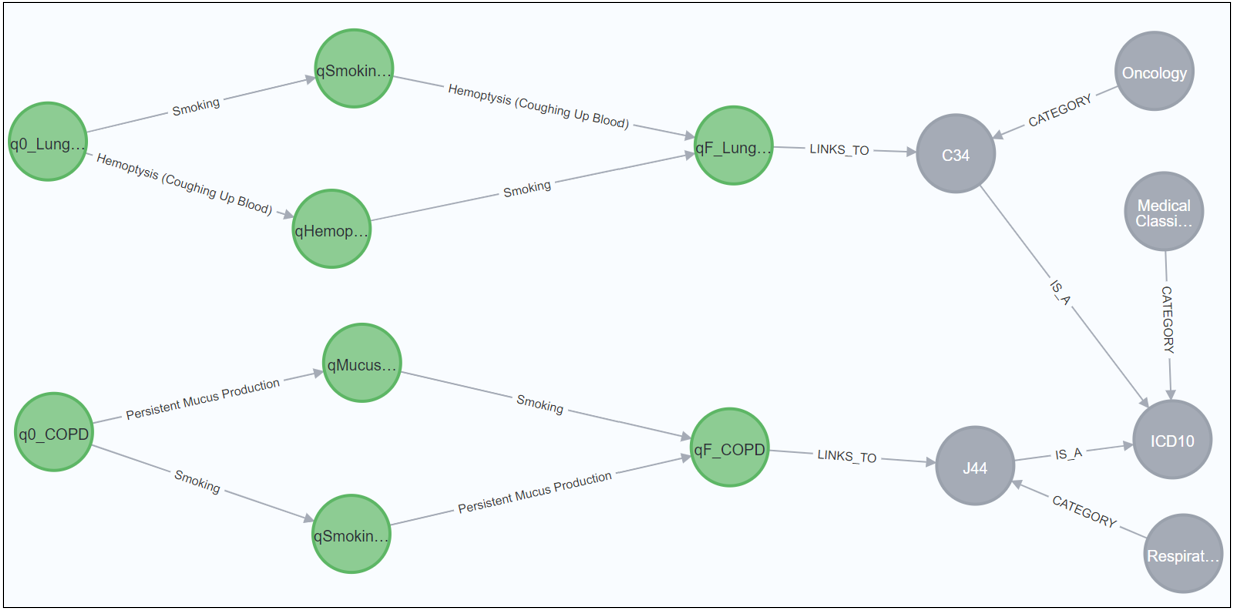
The green nodes represent process states and transitions within the NFAs for two medical conditions. The gray nodes represent categories and relationships from a typical ontology:
Certainly, the NFAs could be represented with the usual ontology predicates. The example in Figure 3 is typically included into KGs. The typical ontological semantics are that the world consists of things—objects and events—and these things have sets of attributes/properties, which in turn have attributes and properties.
But in the NFA form, and given the proper platform, we could have thousands of these rules processed in near-real-time, in massively parallel fashion—with a single, very simple algorithm. Adding it to the KG simply adds the knowledge in a way that preserves its intended semantics, into a centralized structure.
Use Case Scenarios
- Healthcare Workflow Monitoring:
- The NFAs can monitor patient event sequences in real time (e.g., smoking, mucus production, coughing up blood) and flag potential diagnoses early.
- Knowledge Graph Querying:
- Ontologies provide context for diagnosis codes, enabling semantic queries like “Find all respiratory diseases.”
- Anomaly Detection:
- If an observed sequence doesn’t match any known NFA path, it could indicate an anomaly in the patient’s condition or process.
Micron’s Automata Processor vs. Reps NFA Implementation
The Micron Automata Processor was an innovative hardware architecture designed to implement NFA directly in silicon, enabling massive parallelism for pattern recognition tasks. By leveraging DRAM technology, the AP could process thousands of NFAs simultaneously for each input symbol, effectively broadcasting a request to an entire array of automata rather than querying each sequentially. This approach allowed for high-throughput and efficient pattern matching, making it particularly suitable for applications in bioinformatics, network security, and big data analytics.
At one point, early on in the life of the AP (2014-ish), I presented to Micron a BI application for the AP—it had the typically geeky name of APBIA (Automata Processor Business Intelligence Appliance). We could collect machine learning models (in a way that resembles what I talk about for Prolog in Prolog in the LLM Era-Part 7) from across an enterprise, convert the ones that could be converted into NFA (ex. decision trees/forests, time series, and association rules), implement all of them on a bank of AP, and recognize thousands of ML rules in parallel as symbols streamed in.
However, despite its promising capabilities, the Micron Automata Processor is no longer in active production.
So a few years ago (2015-ish) I developed a software implementation of a scalable NFA processor called Reps—named after Paul Reps, a Zen pioneer in the West. While it’s not nearly as fast as Micron’s Automata Processor—a specialized NFA chip that faced challenges like overheating—it is highly scalable and practical for many real-world applications.
NFAs can be built from the events we capture in subject-integrated event infrastructures (for example, built on Kafka or Azure Event Hub). They can also be converted from ML models that naturally lend themselves to NFA conversion, such as decision trees, association rules, and clustering algorithms. Additionally, NFAs can be manually designed from workflows crafted by domain experts, especially with AI assistance to streamline and validate the process.
Each NFA is an icon of the countless dynamic, cyclical processes that underpin life. They sense the events emitted by real-time, real-life processes, collectively capturing the state of the world at any given moment. An NFA-based system can answer critical questions: What processes are currently in progress? What states are they in? What patterns or anomalies have been recognized? How are they trending over time?
Such an NFA implementation can serve as a form of real-time awareness, essential for any intelligence system. Without a clear understanding of the current state of the world, how could true intelligence exist? NFAs provide the backbone for this awareness, offering a framework to monitor and react to the ever-changing flow of life’s events.
Reps can process thousands of sequences in parallel (albeit, not fully parallel as is the AP), making it ideal for tasks like event processing, workflow validation, and sequence recognition. It can scale across a cluster of servers and the cores in each node, partitioning by sets of rules. I’ll probably show it off a bit during my Knowledge Graph Structures session at DMZ 2025.
I did want to write a version of Reps founded on GPUs—which will work well since NFA can be expressed as a matrix of states by transitions. I think it will be at least close to the performance of the AP and certainly magnitudes faster than the current software-based version of Reps. But:
- It is a very hefty project (high-scale system) and there are too many other things to do right now. There’s more to the project than just the GPU/NFA part.
- A few packages for running NFAs on GPUs have emerged since I created Reps back in 2015. I like this paper: ngAP: Non-blocking Large-scale Automata Processing on GPUs
See You at DMZ 2025
NFAs represent a simple yet powerful computational model that has applications far beyond traditional computing theory. By integrating NFAs, strategy maps, and other unconventional knowledge structures into knowledge graphs, we can expand our ability to represent and analyze complex systems.
There is so much to cover concerning NFA and how it can play a very important role in a richer AI. Some of that will be in my follow-up book (due Q1 2025) … or in the one after that.
I look forward to presenting and discussing these ideas and more at DMZ 2025—hope to see you there! There will be many very talented folks speaking there. And there are two 8+ Dave Portnoy-rated pizza places we must visit:
