As I mentioned in a previous post, Sample From My Talk – NFA, I will be delivering two sessions at the Data Modeling Zone 2025 (DMZ) in Phoenix. It will be happening from Tuesday, March 4, 2025 through Thursday, March 6, 2025. That post included a preview one of my two sessions, Beyond Ontologies and Taxonomies—focusing on Non-Deterministic Finite Automata. This post is also a preview of that session, focusing on another structure—trophic cascades.
The release of DeepSeek R1 a week ago provides a great business example of a trophic cascade—that of the AI ecosystem. The main point of this Trophic Cascade of AI exercise is to demonstrate to my BI audience the value of the trophic cascade. Coincidently, DeepSeek is a very current trillion-dollar (NASDAQ, Nvidia losses-which should be temporary) example of a disruption to a trophic cascade. No one can afford not to be aware of these sorts of relationships that are well beyond the kind of information in typical ontologies and taxonomies of knowledge graphs.
The Black Swan-like disruption (hey, two cliche’s in a row, courtesy of Taleb and Christensen) caused by the release of DeepSeek is still powerfully fresh on everyone’s mind that it serves as a timely example of a trophic cascade. In this blog, I will describe one way to think about the trophic cascade of AI. I emphasize one way because such models involve a good deal of artistry and critical—even original—thinking. Meaning, there are many ways to express something complex—some better or worse than others for various reasons.
But first, I’ll provide a little background on trophic cascades, in case you need a refresher. I’m pretty sure almost everyone has encountered this concept in even high school biology.
Trophic Cascades Background
Dr. Robert Paine spent a lot of time during the early 1960s on the beautiful coastlines of the Pacific Northwest, watching how species interacted in tidal pools. One of the big questions that stuck with him was: why don’t populations just keep growing until they take over everything? If food is available (mussel food is plankton, which is constantly refreshed by the nutrient-rich coastal waters), why don’t mussels completely dominate? What’s keeping everything in check?
He realized that something had to be actively regulating populations—something beyond just competition for resources. The answer, as it turned out, wasn’t just about who was eating what. It was about who was keeping who in check and what happened when you removed a key species from the system.
His experiments led to some of the most famous discoveries in ecology, particularly in how top predators can shape entire ecosystems in ways that aren’t obvious at first glance. His two best-known case studies—the starfish experiment in intertidal pools and the sea otter-urchin-kelp cascade—showed just how deep these interactions go.
The Starfish Trophic Cascade – The Birth of Keystone Species
In the 1960s, Dr. Paine was studying the rocky tide pools of Washington State when he noticed something that stuck with him—a starfish prying open and eating a mussel hidden beneath the surface. It made him wonder: What would happen if these starfish weren’t here? Would mussels still be kept in check? Would something else take their place as mussel predators? Or would the ecosystem shift in some unexpected way? What other predators do mussels have? What about the mussels’ prey?
To find out, he set up what was basically a real-world ecological experiment. He started yanking ochre starfish (Pisaster ochraceus) out of tide pools to see how the system would respond. Can you imagine doing that today? And then he waited for some months to see what would happen.

Without the starfish keeping things in check, mussels took over, outcompeting everything else and wiping out biodiversity. The ecosystem went from a complex mix of species to basically a monoculture of mussels. It meant that some predators don’t just “influence” an ecosystem—they define it.
That’s when he came up with the concept of “keystone species”. That is, species that, if removed, cause an ecosystem to collapse in ways no one would predict just by looking at their population numbers. Note that “keystone species” is not necessarily the apex predator—although they are often the same.
The Sea Otter Trophic Cascade – A Predator That Grows Forests
His second big trophic cascade discovery was in collaboration with James Estes, and this time, it wasn’t just a tide pool experiment—it was playing out across the vast kelp forests of the Aleutian Islands in the North Pacific. They noticed something weird. In areas where sea otters were thriving, kelp forests were lush and healthy. But where sea otters were missing, the kelp was gone.
The reason? Sea urchins—yes, as in uni.
Sea otters love to eat urchins, and without otters around, urchins go unchecked and turn into underwater lawnmowers, chewing through kelp at a wild rate. Take away the otters, and you don’t just get more urchins—you lose the entire kelp forest. This wasn’t just a neat little predator-prey interaction—it showed that top predators don’t just limit their prey; they control entire ecosystems.
But why were sea otters disappearing? The leading hypothesis is that orcas had started hunting them. Normally, orcas prefer larger marine mammals like seals and sea lions, but the idea was that overfishing by humans lead to the depletion of those seal and sea lion populations, leaving the orcas with fewer options.
This is actually a whole other trophic cascade—the disruption by the addition of human fishing:
orcas-eat->seals-eat->fish<<-hunt-humans
With their usual prey scarce, orcas possibly turned to sea otters, throwing the whole ecosystem off balance. The orca trophic cascade was a disruption to the otter-urchin trophic cascade they were studying! I think orcas always ate otters, but the seals were more plentiful and perhaps easier to catch since the otters too were sheltered by the kelp beds.
I think the otters are back, and all is well, but we missed an opportunity of massive predation from uni sushi lovers.
The figure below shows that the trophic cascade starts out with just a food chain as first iteration. The food chain nature implies the trophic cascade is about nutrition. However, the valuable information is more than about what eats what. Further iterations incorporate inferred relationships such as how one creature eats another and how creatures utilize features of its environment to prevent being eaten and/or promote its chances for eating.

In fact, the high coastal erosion along the California coast might, at least in part, be due to the loss of kelp forests, which were decimated by the over-hunting of sea otters—this time by people, not hungry orcas. The return of otters after hunting ended allowed the kelp forests to recover, helping to stabilize the coastline.
Both of these examples helped lock in the idea that ecosystems aren’t just collections of species—they’re dynamic systems where removing one key player can cause massive and surprisingly out-sized chain reactions. Paine’s work wasn’t just academic—it changed how we think about conservation, species reintroductions, and might even help with modern AI-driven ecosystem modeling.
Trophic Cascade Definitions
In the context of “trophic cascades”, trophic refers to the feeding relationships or the nutritional levels within an ecosystem. The word trophic comes from the Greek word trophē, meaning nourishment or food. For our case of AI, the metaphorical trophē are possibly money, AI dominance.
This phenomenon occurs when a change in the abundance of one species at one level of the food chain (often a top predator, but not always) leads to a cascade of effects down through the other levels. For instance, if apex predators like wolves are removed from an ecosystem, this can lead to an increase in the number of their prey (like deer), which might then overgraze vegetation, affecting plant communities and even altering physical landscapes.
An interesting quality of the trophic cascade are hierarchical steps in a food chain, where each level represents a group of organisms that share the same function in the food chain:
- Primary Producers – The foundation of the food web. These organisms convert solar energy into chemical energy. Kelp forests along the California coast, which grow by absorbing sunlight and nutrients from the water. Seagrass meadows, which provide food and habitat for marine herbivores.
- Primary Consumers (Herbivores) – Organisms that eat primary producers. Crabs grazing on seagrass, Zooplankton feeding on microscopic phytoplankton, Sea urchins devouring kelp, which can lead to kelp forest decline if not controlled.
- Secondary Consumers (Carnivores that eat Herbivores) – Predators that feed on primary consumers. Examples: Sea otters, which feast on sea urchins, keeping kelp forests healthy. Squid, which prey on small fish that eat plankton.
- Tertiary Consumers (Top Carnivores) – Predators that consume secondary consumers. Orcas (killer whales), which sometimes hunt sea otters or even sharks. Examples: Great white sharks, which prey on sea lions that feed on fish.
At each level, “energy” is transferred up the food web, but only a small percentage of the energy moves to the next level (that 10% rule we all learned in grade school), meaning top predators require large ecosystems to sustain them.
The Trophic Cascade of AI
Here is a very simple take on the AI Trophic Cascade, just to demonstrate the idea. It includes just a few nodes.
In reality, most entities aren’t so simple that they play only one role. The world is complex, organizations are complex. Most entities here aspire to be the keystone species and/or apex predator. For example, Microsoft is the largest investor in OpenAI and provides the compute infrastructure for OpenAI. But it’s also consumer of human expertise, it produces many almost ubiquitous products, it’s one of the Cloud powerhouses, has AI aspirations of its own that probably will compete with OpenAI, and it’s a very rich company. A company like that will occupy many roles.
Strictly speaking, the “trophic cascade of AI” isn’t a true trophic cascade since “trophic” generally refers to ecologies. More generally, it’s a form of “influence network” (or causal or dependency), where changes at one level propagate through interconnected dependencies. For now, let’s continue calling it a trophic cascade since the AI space in kind of like an “ecology”, where models, data, and users form an interdependent system with feedback loops.
Below is a take on the Trophic Cascade of AI from a GPU-focused point of view.
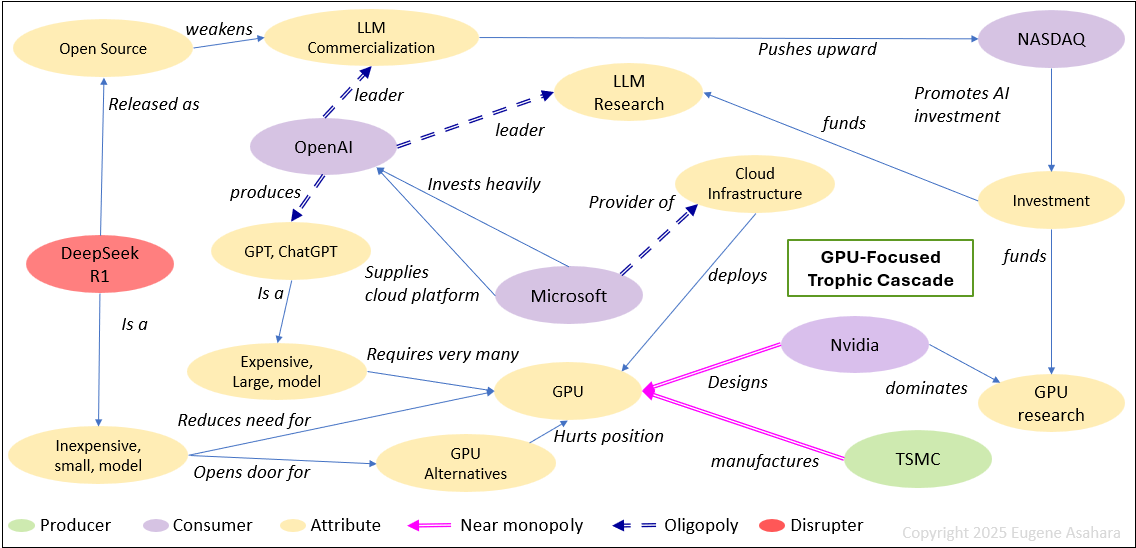
These entities are the consumers (top of the chain) that consume and dominate others by setting the direction of AI and semiconductor development.
- OpenAI: Dominates LLM research & commercialization (ChatGPT).
- Microsoft: Major AI investor (OpenAI partnership), cloud infrastructure leader (Azure).
- NASDAQ: Provides financial capital & valuation incentives that drive investment.
- Nvidia: Dominates GPU and AI chip markets, but faces competition from new AI models optimized for non-Nvidia hardware.
TSMC is the only producers of this trophic cascade, manufacturing semiconductors that power Nvidia GPUs, Microsoft cloud AI, and OpenAI models. It makes one of the primary resources out of sand.
Disruption by DeepSeek R1’s Open-Source AI Release
I don’t intend to fully cover this disruption and the cascading effect DeepSeek has on the AI world in this blog. The DeepSeek thing is just an example for me to introduce trophic cascades ahead of my talk.
In a nutshell, DeepSeek R1 is the introduction of a highly capable open-source AI model, challenging OpenAI’s dominance. As a result, businesses might increasingly adopt open models rather than relying on OpenAI’s proprietary APIs. This shift could lead to a decline in demand for OpenAI services, reducing revenue for Microsoft Azure AI, which hosts and monetizes OpenAI’s models.
At the same time, as open models gain traction, the need for Nvidia’s GPUs could decrease opening the door for non-GPU hardware such as Google TPUs, RISC-V AI chips, or specialized AI accelerators. While TSMC continues to benefit from semiconductor manufacturing, the demand for AI chips may diversify beyond Nvidia, shifting to other players in the industry.
Just for kicks, let’s think of a couple other disruptions as a trophic cascade.
What if TSMC Faces a Crisis? (Geopolitical Disruption)
A major disruption to TSMC’s semiconductor production, whether due to geopolitical tensions, natural disasters, or supply chain failures, would send shockwaves across more than the AI industry. Nvidia, Microsoft, and OpenAI, all of which rely on TSMC’s advanced chip manufacturing, would face severe chip shortages, slowing down AI progress and cloud computing capabilities.
Of course, financial markets would react swiftly—NASDAQ would likely experience a sharp and deep drop in semiconductor stock prices, triggering a global ripple effect as technology firms struggle to secure alternative chip suppliers.
Government Disruption
Certainly, DeepSeek must have caused some disruption for the Project Stargate folks. When President Trump stood with Sam Altman, Larry Ellison, and Masayoshi Son on January 21, 2025, to announce the $500 billion Project Stargate, I wondered if President Trump ever heard of Moore’s Law. Out of that bunch, I assume Larry Ellison and Sam Altman have. I’d be a little worried about committing such a tremendous amount of resources the middle of the current chaos of the AI world.
At the time of writing, I don’t believe we know how the $500 billion is allocated, but it seems like the primary objective is to build infrastructure. I also imagine this commitment is intended for sooner than later since AI advancement moves faster than pretty much everything else.
You know, having used LLMs for hours every day since November 2022, for now and for the most part, it’s just smart enough to be dangerous. It’s too early to settle on what we have now and run with it. At some point in an IT project (and Project Stargate is the mother of all IT projects), you need to settle on what is the current stack and commit to it. I just don’t think that time is here.
Some form of Moore’s Law has already been in play in the AI world since OpenAI’s release of ChatGPT 3.5 back in November 2022. The rate of change and improvement in AI is so relentless and unpredictable today that those data centers might start to look like the 21st century version of $500 billion dollars of VHS tapes and players. But in all fairness, the Big Data world has done well to either replace older servers with new ones or offer the older ones as a cheaper option.
For example, with NVIDIA’s advancements since November 2022, data center GPUs like the H100 and now the Blackwell-based B100 have become at least several times more powerful, drastically shifting the AI landscape in just a couple of years. That’s the equivalent of multiple Moore’s Law cycles in a short span, reflecting the unprecedented pace of AI hardware evolution.
From a Moore’s law point of view, DeepSeek brought down the cost of training at least 10x (so they claim). The cost of inference on those models—I would think no worse than for OpenAI. Quality of the answers-it seems close to equal, just a bit worse than the big LLMs. Anyway, there’s a few Moore’s Law cycles in there.
Spending a few hundred million dollars on training and the ongoing inference of LLMs is different from spending three magnitudes more on infrastructure that is likely to become quickly obsolete.
Back to My DMZ 2025 Session
While the links in a trophic cascade should be based on empirical observations, the implications are often hypothetical. For example, when Dr. Paine experimented with eliminating starfish, he didn’t know what would happen until he went back months later to see the results. But that’s OK. The trophic cascade encapsulates wisdom of subject matter experts such as Dr. Paine. In a business setting, trophic cascades encapsulate the wisdom of experienced analysts and managers.
Even though the value of a trophic cascade might seem valuable only in hindsight, they tell a story, stories with a moral ending—just like a parable, a fable, etc.—just in graph form. The lessons in such stories are earned the hard way through critical and original thinking and often the hard knocks that are the moral of the story. These stories should be incorporated into knowledge graphs along with ontologies and taxonomies.
I mentioned earlier that a trophic cascade might be something just known by another name— for example, causal network and dependency network. What I think defines trophic cascades is the intent of the model. For example, it’s part risk management. Where are the vulnerable points? What could happen if a “player” vanishes from the playing field?
As just mentioned, the assertions might be completely hypothetical. Many would object to the inclusion of hypotheses (as opposed to proven knowledge) included in a knowledge graph. But a hypothesis is an idea, a very rare thing in the Universe. A hypothesis is an idea that may not be immediately provable but nonetheless, it shines a light on problems, provides direction, so we may be forced to include it in our plans and decisions. For example, at the time of writing, the consensus is we haven’t achieved AGI, but a big part of the world is spending an awful lot of resources in preparation for it.
The trophic cascade is an encoding of understanding—beyond knowledge, at worst, merely information. Traditionally, this understanding is conveyed in natural language in the form of books and articles. That’s fine. LLMs could add that text to their training. It could even output a good draft of a trophic cascade from the writings, which could be applied to a knowledge graph.
Why is adding that to a knowledge graph of value when the LLM can instead be trained with that information? Because the knowledge graph is transparent to us, and we have direct control over it. That is unlike LLMs that are opaque, and we can only control it indirectly through its training. That’s precisely why my books, Enterprise Intelligence and the soon to be released Time Molecules are focused on building enterprise knowledge graphs as AI structures.
Remember when I said a trophic cascade is one way to encode your ideas? It’s a work-in-progress as you hone the ideas link by link over many iterations from a set of causal hypotheses into a bonafide theory. At each iteration, your current beliefs embedded in your enterprise knowledge graph adds value. Ideas are our currency for more than gaining a mere competitive edge, which are always temporary and usually just incremental. Leave all that mundane stuff to AI and use your life to express the product of your unique experiences, curiosity, and personality.
